凤凰项目:一个IT运维的传奇故事
The Phoenix Project
A Novel About IT, DevOps, and Helping Your Business Win
[美] 基恩·金 (Gene Kim) 凯文·贝尔 (Kevin Behr) 乔治·斯帕福德 (George Spafford) /著
COO = Chief Operation Officer 首席营运官
CIO = Chief Information Officer 首席信息官 / = “Career Is Over” 职业生涯结束了
ITIL = Information Technology Infrastructure Library 信息技术基础架构库
ITSM = Information Technology Service Management 信息技术服务管理
WIP = Work in Process 在制品
经典语录
有些书适合给你的朋友,为了分享阅读的喜悦;有些书适合给你的同事,为了建立理念的共识;有些书适合给你的老板,为了播下伟大的种子。
电影《拯救大兵瑞恩》:这里有一系列的命令:只可对上抱怨,不许对下牢骚。
虚构人物语录
比尔·帕尔默:
- 要想在IT运维管理的岗位上做得长久,一定得有足够的资历,这样才能把事情干好。但是一定要低调,不能卷入政治斗争,以免惹祸上身。副总裁们整天做的就是互发PPT。
- 俗话说得好,如果你的同事主动告诉你他们要离职,那多半是自愿的。但如果是其他人告诉你的,那他们一定是被迫的。
- 海军陆战队,保持军营干净整洁不只是为了美观,更是为了安全。
- 靠道听途说可没法破案,当然也没法解决服务中断故障。
- 知道真相总好过一无所知。
- 再也没有比阻止人们去做他们理应做的事更能毁掉大家的热情和支持了。我不认为我们还能有第二次机会让事情走上正轨。
- 80/20法则在这里似乎同样适用:80%的风险是由20%的变更造成的。
- 流程是用来保护人的。
- 埃瑞克把半成品称为“沉默的杀手”,车间控制半成品的能力不足,是造成长期性延误和质量问题的根源之一。
- 搞死你的不是前期投入,而是后台的运行和维护。
- 告知真相是一种爱的表现。隐瞒真相是一种恨的表现。甚至更糟,是一种冷漠的表现。
- 开发和QA的环境与生产环境不匹配,绝对不应该发生这样的事。
埃瑞克:
- 只有掌握了战术,才能实现战略目标。
- 半成品是个隐形杀手。因此,管理任何一家工厂最关键的机制之一,就是工作任务和原材料的发布。没有这个机制,就无法控制半成品。
- 不应该根据第一个工作站的效率来安排工作,而是根据瓶颈资源所能完成工作的速度来安排工作。
- 创建约束理论的艾利·高德拉特告诉我们,在瓶颈之外的任何地方做出的改进都是假象。(所有在非约束点所做的改进都是假象)
- 作为IT运维部的副总裁,你的工作是确保形成一条迅速、可预测、持续不断的计划内工作流,从而向业务部门交付工作价值,同时尽可能降低计划外工作的影响和破坏,那样你才能提供稳定的、可预期的、安全的IT服务。
- 反复实践是精通工作的先决条件。
- 不仅仅是要减少半成品。相比于向系统中投入更多的工作,将无用的工作剔出系统更为重要。
- 重要的是结果,而非过程、管理,或者你完成了哪些工作。
- 每个工作中心都由四种东西组成:机器、人员、方法,以及测评。
- 研究表明,每天训练5分钟比每周开展一次为期3小时的训练更有效。
- 一个给定资源的等待时间,是那个资源忙碌时间的百分比除以空闲时间的百分比。因此,如果一个资源使用了50%,等待时间就是50/50,或者说1个单位。
- (信息安全)可以不对IT系统做过多无用功就保护公司,这才是你的胜利。如果你能把那些无用功剔出IT系统,你的胜利就更进一步。
- 把整个环境创建流程自动化。
- 要记住,你身边有很多经验丰富的人,他们也踏上过同样的旅程,所以,你可别因为不去找人帮忙,而变成一个失败的傻瓜啊。
- 一时的救世主固然好,但普世的圣经则更有用。
史蒂夫:
- 一个伟大的团队并不代表他们拥有最聪明的人。使团队变得伟大的因素,是每个人都互相信任。当那种神奇的动力出现,就会让整个团队充满力量。(凝聚力)
- 兰西奥尼教导我们,展现自己脆弱的一面有助于建立起信任的基础。
- IT不只是一个部门。相反,它就像电力一样无处不在。IT是一种技能,就像能读会算一样。
- 每一个称职的COO都会是从IT部门出来的。任何尚未精通IT系统就负责管理公司运行的COO,都只会是金玉其外的傀儡,需要依靠别人来开展工作。
玛姬·李:
- 在竞争的时代,游戏规则就是“快速上市,快速淘汰”。我们需要短而快的周期,不断整合来自市场的反馈。
现实人物语录
卡伦·马丁和麦克·奥斯特林《Value Stream Mapping》:
价值流:一个组织基于客户的需求所执行的一系列有序的交付活动,或者是为了给客户设计、生产和提供产品或服务所需从事的一系列活动,它包含了信息流和物料流的双重价值。
爱德华·戴明博士:没人会强迫你学习……学习也并非生存必需。(自驱的学习才有用)
克里斯托弗·利特尔:DevOps不仅是自动化,就像天文学不只是望远镜一样。
通用电气公司 首席执行官 伊梅尔特:没有将软件作为核心业务的每一个行业或公司都会受到影响。
微软 技术院士 杰弗里·斯诺弗:在过去的经济时代,企业通过移动原子创造价值。而现在,他们必须通过数字创造价值。
克里斯托弗·利特尔:每个公司都是科技公司,无论他们认为自己处在哪个行业。银行也只是拥有银行执照的IT公司而已。
高德拉特博士《目标之外》:在任何价值流中,总是有一个流动方向、一个约束点,任何不针对此约束点而做的优化都是假象。
休哈特:循环(即PDCA环)——计划(Plan)、实施(Do)、检查(Check)、改进(Act)。
麦克·奥泽恩:比日常工作更重要的,是对日常工作的持续改进。
帕特里克·兰西奥尼《团队发展的五大障碍》:
1.缺乏信任;2.惧怕冲突;3.欠缺投入(投入激情);4.逃避责任;5.无视结果。
项目管理
变更:对应用程序、数据库、操作系统、网络或硬件进行的物理、逻辑或虚拟操作,并且这样的操作可能对相关服务产生影响。
技术债务:沃德·坎宁安首次提出。类似于金融债务。我们当前所做出的决定会导致一些问题,而这些问题随着时间的推移会越来越难解决,未来可采取的措施也越来越少。即使我们审慎地承担技术债务,也依然会产生利息。
分钟级别的部署前置时间的方法:
向版本控制系统中持续不断地提交小批量的代码变更,并对代码做自动化测试和探索测试,然后再将它部署到生产环境中。这样,我们就能对代码变更在生产环境中的成功运行保持高度自信,同时还能快速地发现并修复可能出现的问题。
预防措施有个问题,就是你很少能知道自己究竟避开了哪些灾难。
要想在现代技术上取得成功,必然需要多方向和多专业领域的协作。
想要在团队中达成相互信任,你需要展现出自己脆弱的一面。
更卓越的领导力其实是为团队创造条件,让团队能在日常工作中感受到这种卓越。
产品负责人不应该只关注具有创新性的产品和功能,还需重视维护工作和移除技术债务等优先级。
任何一个领域或学科想要取得进步和成熟,就需要认真反思它的起源,在反思中寻求不同的观点,并把这些不同观点的来龙去脉思考清楚,这对预见未来发展是非常有帮助的。
IT运维、信息安全和开发等不同职能部门之间的良好合作是成功的关键。
一个IT做得失败的公司,整个公司也都是失败的。
IT公司的任务和价值:
- 对变化莫测的市场做出反应;
- 为客户提供稳定、可靠和安全的服务。
界定问题的性质:
1.经常发生的问题——流程制度
2.偶然发生的问题——规则方法
3.首次发生的“经常问题”——重点决策
提高效率三要素:稳定环境,减少切换成本;可视化目标,掌握全局;紧紧盯住约束点,抓住关键。
四类工作:业务项目,内部项目,变更,计划外工作(破坏性最强)。
五个聚焦步骤:
1.确认约束点。找不到真正的瓶颈,做什么都是多余。
2.利用约束点。不能让约束点闲着,让它一直运转,而不是需要他才运转。
3.迁就约束点。以瓶颈的产出速度作为整个项目的产出速度。使布伦特解决完一个关键后马上解决下一个关键问题,只做关键工作,疏通瓶颈,避免半成品过剩。
4.消灭约束点。可以通过增员,引进新技术,跳过瓶颈等方式提高瓶颈产出速度,降低瓶颈对项目进程的约束。
5.发现新的约束点。主要矛盾被解决后,次要矛盾会上升为主要矛盾。在约束点被消灭后,找到新的约束点,聚焦它,将进一步提高产能。工作流将越来越流畅高效。
DevOps
DevOps = Development & Operations 开发和运维
infrastructure as code 基础设施即代码
CI = Continuous Integration 持续集成
CD = Continuous Deployment / Continuus Delivery 持续部署/持续交付
“每日10次部署”
DevOps的准则:总有更好的方法
DevOps的原则和模式就是通过整合企业文化、企业架构和技术实践,让下降式螺旋变成上升式螺旋。
DevOps是把精益原则应用到技术价值流中的结果。
DevOps基于精益、约束理论、丰田生产系统、柔性工程、学习型组织、安全文化、人员优化因素等知识体系,并参考了高信任管理文化、服务型领导、组织变动管理等方法论。
精益的两个主要原则:
- 坚信前置时间(把原材料转换为成品所需的时间)是提升质量、客户满意度和员工幸福感的最佳度量指标之一
- 小批量任务的交付是缩短前置时间的一个关键因素
在DevOps中,技术价值流:把业务构想转化为向客户交付价值的、由技术驱动的服务所需要的流程。
流程的输入是既定的业务目标、概念、创意和假设,始于研发部门接受工作,并将它添加到待完成工作列表中。
技术价值流的核心是建立高度信任的文化。
三步工作法:
第一工作法,建立工作流并以可视化方式呈现
第二工作法,根除计划外工作的最大源头
第三工作法,不断给系统增加压力,使其习惯并强化。
三步工作法的原则:
- 流动原则:它加速了从开发、运维到交付给客户的流程。
使工作可见;限制在制品数;减小批量大小;减少交接次数;持续识别和改善约束点;消除价值流中的困境和浪费。 - 反馈原则:它使我们能建立更加安全可靠的工作体系。
在复杂系统中安全地工作;及时发现问题;群策群力,战胜问题获取新知;在源头保障质量;为下游工作中心而优化。 - 持续学习与实验原则:它打造出一种高度信任的文化和一种科学的工作方式,并将对组织的改进和创新作为日常工作的一部分。
建立学习型组织和安全文化;将日常工作的改进制度化;把局部发现转化为全局优化;在日常工作中注入弹性模式;领导层强化学习文化。
更快、更廉价、更低风险的软件交付趋势正加速发展:
| 1970~1989 年 | 1990~1999 年 | 2000 年~至今 | |
|---|---|---|---|
| 时代 | 主机 | 客户端/服务器 | 商品化和云计算 |
| 标志性技术 | COBOL、运行在MVS上的DB2等 | C++、Oracle、Solaris等 | Java、MySQL、RedHat、Ruby on Rails、PHP等 |
| 交付周期 | 1~5年 | 3~12个月 | 2~12个星期 |
| 成本 | 100万~1亿美元 | 10万~1000万美元 | 1万~100万美元 |
| 风险级别 | 整个公司 | 产品线或部门 | 产品特性 |
| 失败成本 | 破产、出售公司、大量裁员 | 业务亏损、CIO革职 | 可忽略不计 |
罗恩·韦斯特拉姆的组织类型学模型:
| 病态型 | 官僚型 | 生机型 |
|---|---|---|
| 隐瞒信息 | 忽略信息 | 积极探索信息 |
| 消灭信使 | 不重视信使 | 训练信使 |
| 逃避责任 | 各自担责 | 共担责任 |
| 阻碍团队的互动 | 容忍团队的互动 | 鼓励团队间结盟 |
| 隐瞒事故 | 组织是公道和宽容的 | 调查事故根因 |
| 压制新想法 | 认为新想法会造成麻烦 | 接纳新想法 |
思想感悟
- 浴火重生的叫凤凰,浴火成灰的叫火鸡。
- 获得别人好感,拉进别人距离的好办法就是很自然的说出这个人的一些事儿。
- 在约束理论中曾经提到过,所有人都在忙碌是一件很可怕的事情,这不是高效的表现。所有在非瓶颈处的更高效率都是无用功,甚至可能有副作用。
- 工作的动力大部分是成就感,而不是一直被某些人或者事情追着跑。需要时间静下心来思考。
IT技术,应用层日新月异,要保持学习;底层变化不大,要夯实基础。基础不牢,地动山摇。
独角兽项目:数字化转型时代的开发传奇
The Unicorn Project
A Novel about Developers, Digital Disruption, and Thriving in the Age of Data
[美] 吉恩·金 /著
ITIL = Information Technology Infrastructure Library 信息技术基础架构库
TEP-LARB = Technology Evaluation Process - Lead Architecture Review Board 技术评估流程表-首席架构审查委员会
STEM:Science 科学,Technology 技术,Engineering 工程,Mathematics 数学。
FAANG:美国市场上五大最受欢迎和表现最佳的科技股的首字母缩写,即社交网络巨头Facebook(NASDAQ:FB)、苹果(NASDAQ:AAPL)、在线零售巨头亚马逊(NASDAQ:AMZN)、流媒体视频服务巨头奈飞(Netflix,NASDAQ:NFLX)、谷歌母公司Alphabet(NASDAQ:GOOG,NASDAQ:GOOGL)。
HPPO效应:Highest Paid Person’s Opinion,最高收入者意见。
big wad of crap 一大团废物
名词术语
- 竞态条件 race condition:设备或系统出现不恰当的执行时序,而得到不正确的结果。从多进程间通信的角度来讲,是指两个或多个进程对共享的数据进行读或写的操作时,最终的结果取决于这些进程的执行顺序。
- “海森堡 bug”:观察行为改变了现实本身性质的量子物理现象。
- 亚马逊的“两个比萨团队”原则:用两张比萨可以喂饱的团队就能创建出功能特性。
- 塔克曼的团队阶段模型:形成期、动荡期、规范期和高效期。
- 混沌工程:在生产环境中对软件系统进行实验的学科,目的是建立对系统承受动荡和意外情况能力的信心。
- 惊群问题:同时进行的客户端重试最终导致服务器挂掉。在计算机科学中是指,如果许多进程在等待一个事件,事件发生后这些进程被唤醒,但只有一个进程能获得CPU执行权,其他进程又得被阻塞,从而造成严重的系统上下文切换代价。
- 现金牛 cash cow:拥有高市场占有率及低预期增长的业务。
- 霍尔原则 Hoare principle:写代码有两种方法:写得非常简单,显而易见没有bug;写得非常复杂,没有显而易见的bug。
- 沃德利映射 Wardley Map:从客户的需求入手,逐步绘出满足这些需求的各个功能和系统,以及这些功能和系统的演进,以呈现出组织内部存在的价值链。
- 美国心理学家库伯勒−罗斯(Kübler-Ross)将身患绝症的患者从获知病情到临终时期的心理反应和行为改变归纳为5个典型阶段:否认期、愤怒期、讨价还价期、抑郁期和接受期。
经典语录
- 孤立地理解系统的任何部分都是很困难的。
- 信任的缺乏和太多嘈杂的信息让事情进展得越来越慢。
- 能够测试并将代码部署到生产环境更有助于提高产能和客户满意度,而且有助于程序员提升对代码质量的责任感,同时使其工作变得更令人愉悦、更有价值。
- 优秀的 QA 需要一种反常的、有时甚至是残酷的直觉,知道什么会导致软件爆炸、崩溃或无休止地挂起。
- 每个人都能及时将自己的变更合并到“主分支”,比如每天一次。这样,合并的变更就不会太大。就像在制造业里,小批量生产可以创造平稳的工作流程,没有相互冲突的中断或灾难。
- 我们甚至不再需要警卫了。我们太喜欢做囚徒了,认为那些栅栏是为了保护我们的安全而设。
- 永远背负这么多未兑现的承诺,真的是一种认知和精神负担。
- 工程师应该编写代码,而不是填写表单。
- 没有优秀设计师的应用常常被戏称为“企业级”的。原文为 enterprisey,用于形容为大型商业公司开发的软件,常用作贬义指过度设计、不合目的。
- 要想表达清晰,就必须思维清晰。要想思维清晰,就必须记录清晰。
- 伟大可以被扼杀,但也可以被修复。
- 当每个人都清楚目标是什么时,团队就会自我组织起来,以最好地实现这些目标。
- 领导者必须以身作则,示范他们期望的行为模式。
- 成年学习者经常掩盖他们正在试图学习一项新技能的事实,无论是学习一门新语言还是学游泳,甚至是上高尔夫球课。这通常是因为他们尴尬或害怕被人看到自己做不擅长的事情。
- 吸引优秀人才有一个意想不到的方式:通过公司令人惊叹的全新开源项目。
- 技术需要嵌入到业务中,而不是与业务无关,或者仅仅是“与业务保持一致”。
- 恐惧文化所造成的破坏性影响。在这种文化中,错误的行为通常会受到惩罚,替罪羊会被解雇。惩罚失败和“枪杀信使”只会让人们掩盖自己的错误。最终,所有创新的欲望都会被彻底磨灭。
- 当人们不能持续构建他们的应用时,灾难通常就在眼前。
- 有比代码更重要的东西是使开发人员能够高效工作的系统。
- 付出大于回报总是好事,因为你永远不知道将来谁可能会帮助你。人脉很重要。
- 当工程师抽象地思考“客户”而不是真实的人时,很少会得到正确的结果。
- 法律谚语:现实占有,九胜一败。指占有人在诉讼中处于有利地位。
一个笑话:一个 QA 工程师走进一家酒吧。点了1杯啤酒。点了0杯啤酒。点了999 999 999杯啤酒。点了1只蜥蜴。点了-1杯啤酒。点了1个 sfdeljknesv。
现实人物语录
孙振鹏:Patrick Debois: DevOps beyond Dev and Ops。意思是DevOps应超越开发和运维,服务于整个企业或组织,更快、更可靠、更安全地交付对用户更优的价值,助力数字化转型,让业务蓬勃发展,让企业基业长青。
张乐:别只惦记着眼前的几捆“白菜”,技术创新实践的星辰大海、未来的无限可能性更令人心潮澎湃!
PowerShell的发明者杰弗里·斯诺弗:Bash 是一种你会携带一生但不会致死的疾病。
虚拟人物语录
史蒂夫:
- 安全永远排在第一位。
- 技术债务就是指造成困难、重复劳动,并降低软件工程师敏捷性的东西。
- 只要一个团队充满激情、致力于完成一项使命,并且拥有对的技能,那么与他们作对就是愚蠢的,因为他们会竭尽全力让一切成为现实。
- 过去几百年甚至未来上千年都会是这样:员工敬业度和客户满意度是唯一重要的事情。如果我们做到了这一点,并有效地管理现金,其他所有财务目标都会自动达成。
- 我们的未来取决于创新。创新不是来自流程,而是来自人。
- 我们的业务是建立在客户信任的基础上的。我们已经向客户承诺,保护他们的隐私和数据。
玛克辛·钱伯斯:
- 开发人员需要一个系统,以便快速并持续地获得关于其工作质量的反馈。如果你没能很快地发现问题,那么最终会在几个月后发现。但到那时,问题已经消失在其他开发人员所做的大量修改中了,而因果关系也会消失得无影无踪。任何项目都无法这样进行下去。
- Oh, the Places You’ll Go。
- 美好的一天是当她在解决一个重要的业务问题时,时间过得飞快,因为她是那么专注,那么热爱这份工作。她处于心流状态,以至于根本感觉不到是在工作。
- 糟糕的一天就是她沮丧得想撞显示器,在网上搜索一些她根本不想学但为了解决手边的问题必须要学的东西。
- 无论你们使用什么语言,最重要的是不断运行你们的程序。经常运行程序的真正好处之一是你们可以看到它在运行。这很有趣,这就是编程的意义。
- 状态突变和循环是非常危险的,而且很难纠正。
- 作为项目的所有者,她把确保每位贡献者都能拥有很高的生产力视为自己的首要职责。
- 在几乎所有其他领域,特别是当你有客户的时候,变化是常态。健康的软件系统是可以按照所需的速度来进行变更的,人们可以很容易地做出贡献,而不需要跨越重重关卡。这就是让一个项目有趣并值得贡献的秘诀,你会经常看到最有活力的社区就是这样的。
- 她能够以专注、流动和快乐的状态来创造东西。她的工作很快得到了反馈。人们可以做自己想做的事情,而不需要依赖很多人。这就是伟大的架构所能实现的。
- 之所以生产部署是任何技术组织中最复杂的活动之一,是因为这需要在组织中进行如此多部门之间的协调。
- 如果你无法获取关于如何使用程序的反馈,又怎能创造出有价值的东西呢?
- 拥有一个优秀的构建过程是得到良好的代码部署和发布过程的关键。
- 每个决策都是一种承诺,要支持好几年甚至几十年——这远远超出了某个团队的能力范围。
- 找到同类,这就是有效的人际网络的意义所在——你可以召集一群积极的人来解决一个大问题,即使这个团队看起来一点也不像官方组织。
- 之所以痛苦,是因为合并的规模太大了。为了减少痛苦,他们需要更频繁地进行合并,这样合并的规模就会变小,产生的冲突也会更少。
- 环顾四周,她发现公司里最好的工程师都在努力提高其他人的工作效率。“就应该这样。”
- 如果有什么时候需要勇气和不懈的乐观,那就是现在。
- 他们能够取得现在成就的唯一途径,就是创造一种让人们感到安全的文化,从而去实验、学习和犯错,让人们有时间进行探索、创新和学习。
- 对于如此关键的任务,我们不应该依赖外部服务。当它们不工作或断开我们的调用时,我们需要优雅地进行处理。
- 小不一定能胜大。但是,快一定能胜慢。行动迅速的大块头几乎每次都会赢。
库尔特·雷茨尼克:
- 一旦我们可以持续构建,就能进行自动化测试。有了自动化测试,我们就可以更快、更有信心地进行变更,而不必依赖数百小时的手动测试。我相信,这是让我们更安全、更快、更幸福地交付更佳价值的关键第一步。我们需要在构建或测试过程中发现问题,而不是在部署期间或生产环境上。
- 预防需要诚实,诚实需要无所畏惧。就像诺曼·克尔斯在敏捷最高境界中指出的那样:“不管发现了什么,我们都理解并相信每个人都已经全力以赴,只是受限于他们当时所知道的、他们的技能和能力、可用的资源和手头的情况。”
- 在危机中,我们永远不知道真正在发生什么,而且我们需要为未来做准备。在未来,我们对世界的理解也会同样不完美。
埃瑞克:
- 交织(complect)就是把简单的东西变成复杂的东西。在紧耦合和交织的系统中,几乎不可能改变任何东西。
- 代码部署前置时间、代码部署频率和问题解决时间是软件交付、运营效能和组织绩效的预测指标,它们与职业倦怠和员工敬业度等很多因素相关。
- 简单性很重要,因为它促成了局部性。代码中的局部性使系统保持松耦合,使我们能够更快地交付功能特性。团队可以快速而独立地开发、测试,并把价值传递给客户。
- 底层的架构至关重要,关乎开发人员在日常工作中使用的系统是否高效。
- 创新和学习发生在边缘,而不是核心。必须在第一线解决问题,因为那里每天的工作是由世界上最频繁面对这些问题的前沿专家来完成的。
- 心理安全是卓越团队最重要的因素之一。团队有信心,不会因为有人发言而尴尬,受到否决或惩罚。出现错误时,我们会问“是什么原因导致的”,而不是“是谁导致的”。我们承诺尽一切努力让明天比今天更好。
- 未来需要创建一个动态的学习型组织。在这个组织中,实验和学习是每个人日常工作的一部分。
- 与初创公司相比,现代企业拥有更多资源和专业知识。我们需要的是专注和紧迫感,以及管理价值创造过程的现代方法。
- 沃德·坎宁安:技术债务是你下次想要做出变更时感觉到的。
- 比尔盖茨:如果开发人员必须在实现功能特性和提高安全性之间做出选择,他们必须选择后者,因为这关系到公司的存亡。
- 斯蒂芬·斯皮尔博士:无知是所有问题的根源,唯一能克服它的是学习。
- 爱德华兹·戴明:一个糟糕的制度每次都会击败一个好人。
- 约翰·奥斯帕:每个事故都是一次学习的机会,一次未经同意的计划外投资。
- 乔布斯:安全是一切工作的前提。
- 奥尼尔:每个人都必须对自己的安全和队友的安全负责。如果你看到什么东西可能会伤害到别人,就必须尽快修复。
- 克雷·克里斯坦森:我们自己管理“不够好”的东西,将“非常好”的东西外包出去。
柯尔斯顿:
- 公司的最高层不仅要做正确的事情,而且要把正确的事情做对。按时发布代码就是其中一部分。
戴夫
- 每个开发人员都知道,以后需要在编写功能特性的同时编写自动化测试,而不是在之后。(测试驱动)
黛布拉:
- 事实永远比想法有价值得多。
开发实践
绞杀者模式一般用于传统旧系统(大部分是单体)向微服务架构的改造和迁移的过程中。在旧系统中创建一个绞杀者外层(类似扔了一粒无花果种子在旧系统中),然后随着新功能的引入(无花果发芽生长),最终旧系统慢慢被替换成完整的新系统(宿主死亡)。
编程方法论:
- 命令式编程
关注程序的执行流程和状态,程序员定义执行的步骤,而不是定义要达到的目标。
程序由一系列语句组成,其中包括条件语句、循环语句、赋值语句等。语句由计算机解释器或编译器按顺序执行,程序状态在执行过程中不断变化。程序员需要负责跟踪和维护程序状态,以确保程序按照预期执行。
适用于实现算法、操作系统、驱动程序、图形用户界面等领域。
常见的编程语言包括C、Java、Python、C++等。 - 函数式编程
强调使用函数和避免变量状态和可变数据。
主要是基于数学中的λ演算发展而来,它的基础是数学和逻辑学。
广泛应用于处理函数对象和集合、函数式语言、科学计算、并行和分布式计算、Web应用程序等领域。
常见的函数式语言包括Lisp、Haskell、Erlang、Scala、Clojure等。
纯函数:其输出完全依赖于输入,没有副作用、突变或全局状态访问。
不可变性,使世界变得更可预测、更安全。 - 面向对象编程
以对象为中心,通过封装、继承、多态等机制来组织程序结构和实现功能。
可以提高程序的重用性、可扩展性、可维护性和可读性。
广泛应用于各个领域,包括软件开发、游戏开发、物联网、人工智能、图形用户界面等。
常见的面向对象编程语言包括Java、Python、C++、C#、Ruby等。
DevOps
三个视野(Three Horizons),杰弗里·摩尔博士推广。
客户采纳是一个高斯分布曲线,可以划分为创新者、早期采纳者、早期大多数、晚期大多数和落后者。
波士顿矩阵:
公司若要取得成功,必须拥有“市场增长率”和“相对市场份额”各不相同的产品组合。用这两个维度画一个“二维四象限矩阵图”,并给这个矩阵中的四象限,起了几个形象的名字:现金牛,明星,问题,和瘦狗。
- 现金牛业务
现金牛业务被戏称为“印钞机”,通常有很高的相对市场份额,也因此市场增长率显得低。 - 明星业务
明星业务通常是很有前景的新兴业务,在一个快速增长的市场中,占据了相对高的市场份额。一旦明星业务成为现金牛,公司就进入下一个爆发期。 - 问题业务
问题业务是一些相对市场份额还不高,但市场增长率提高很快的业务。它们最终会成为明星业务,甚至现金牛业务,还是会死掉,是不确定的问题。 - 瘦狗业务
瘦狗业务是相对市场份额很低,也看不到什么增长机会的,食之无味弃之可惜的业务。
波士顿矩阵的四种战略建议:
- 发展战略
就是不惜用“现金牛业务”的收益,大举投入到“问题业务”中,以提高相对市场份额,尽快成为“明星业务”的战略。 - 保持战略
就是不轻易投资新方向,好好养牛,维持市场份额,让“现金牛业务”产生更多的收益。 - 收割战略
对强大的替代产品已经出现的“现金牛业务”,比如柯达的胶卷相机,和发展前景不佳的“问题业务”和“瘦狗业务”,可以考虑尽可能快速收割短期利益,然后准备放弃。 - 放弃战略
对于无利可图的“瘦狗业务”,果断清理、撤销、出售,把资源用在其他有前景的业务上。
核心(Core)与非核心(Context)的概念,也就是四个区域的内涵。
核心是组织的核心能力,是客户愿意付钱换取的能力,也是使投资者奖励的能力。
非核心是其余的一切,包括员工餐厅、办公楼之间的摆渡车,以及公司运营必须要做的成千上万件事。它们通常很关键,比如人力资源、薪酬系统和电子邮件。但是我们的客户不会因为我们为员工提供出色的薪酬服务而付钱给我们。
五大理念:
第一理念:局部性和简单性
第二理念:专注、流动和快乐
第三理念:改进日常工作
第四理念:心理安全
第五理念:以客户为中心
思想感悟
- 在占据了我们有限生命的大量时间的工作中,我们对创造价值的追求是共通的。
- 人们总是说“规矩是死的,人是活的”,而又总是制造出死的规矩来约束活的人。
- 公司盈利的极端:
一个极端是,通过削减成本,把运营中的每一点利润榨取干净,想到了丰田的精益生产;
另一个极端是,构建多维度业务,做大现金牛、培育明星、挖掘问题业务、抛弃瘦狗业务。
快速反馈,持续交付,敏捷迭代
《独角兽项目》比起《凤凰项目》紧急上线时的惊心动魄,更多的是项目的解耦,架构的重构,团队成员的团结协作。
数据转型?:关系型的SQL,到NoSQL,到大数据独角兽项目:定制化推荐和促销功能。
独角鲸:新数据库和 API 网关平台。
独角猫 ci-unikitty:持续集成和部署平台。
美洲豹:数据计算平台。逆戟鲸:分析和数据科学团队
DevOps实践指南
The DevOps Handbook
How to Create World-Class Agility, Rellability, and Security in Technology Organizations
[美] Gene Kim, Jez Humble, Patrick Debois, John Willis /著
Patrick Debois,DevOps之父,致力于通过在开发、项目管理和系统管理之中应用敏捷技术来填补项目和运维之间的鸿沟。
DevOps介绍
三步工作法
DevOps的三步工作法:流动、反馈以及持续学习与实验。
- 流动原则:它加速了从开发、运维到交付给客户的流程。
- 反馈原则:它使我们能建设出更安全可靠的工作体系。
- 持续学习与实验原则:它打造出一种高度信任的文化和一种科学的工作方式,并将对组织的改进和创新作为日常工作的一部分。
DevOps是精益原则、约束理论和丰田套路运动的衍生物。
价值流映射、看板和全面生产维护这些实践起源于20世纪80年代的丰田生产系统。
精益的两个主要原则包括:
- 坚信前置时间(把原材料转换为成品所需的时间)是提升质量、客户满意度和员工幸福感的最佳度量指标之一;
- 小批量任务的交付是缩短前置时间的一个关键因素。
精益的核心——改善套路(Kata)。
价值流映射
制造业价值流定义为“一个组织基于客户的需求所执行的一系列有序的交付活动”,或者是“为了给客户设计、生产和提供产品或服务所需从事的一系列活动,它包含了信息流和物料流的双重价值”。
技术价值流定义为“把业务构想转化为向客户交付价值的、由技术驱动的服务所需要的流程”。
流程的输入是既定的业务目标、概念、创意和假设,始于研发部门接受工作,并将它添加到待完成工作列表中。
及时发现并控制这些问题,直到拥有有效的对策,可以持续地缩短反馈周期和放大反馈环,这是所有现代流程优化方法的一个核心原则,能够创造出组织学习与改进的机会。
第一步:流动原则
- 使工作可见。技术行业的工作内容是不可见的,
- 限制在制品数。
《看板方法:科技企业渐进变革成功之道》的作者David J. Anderson所说:停止开始,开始结束。 - 减小批量大小。
理论上,最小的批量是单件流,也就是每次操作只执行一个单位产品的处理。
小批量生产的在制品更少,前置时间更短,错误检测更快,返工量更少。
批量大小是工作产品在不同阶段间移动的单位数。 - 减少交接次数
- 持续识别和改善约束点
5个关键步骤:
- 识别系统的约束点;
- 决定如何利用这个系统约束点;
- 基于上述决定,考虑全局工作;
- 改善系统的约束点;
- 如果约束点已经突破了,请回到第一步,但要杜绝惯性导致的系统约束。
优化下面的约束点:
- 环境搭建
- 代码部署
- 测试的准备和执行
- 紧密耦合的架构
对于高绩效者来说,不管工程师是处于开发、QA、运维还是信息安全岗位,他们的目标都是尽量提高生产力。
消除价值流中的困境和浪费。
精益中对浪费的常用定义是“使用了超出客户需求和他们愿意支付范围的任何材料或资源的行为”。他定义了制造业里7种主要的浪费类型:库存、过量生产、过度加工、运输、等待、移动和缺陷。
浪费和困境是软件开发过程中导致交付延迟的主要因素。
关于浪费和困境的部分类型:
- 半成品:它指的是价值流里任何还没有彻底完成的工作(例如,需求文档或尚未审核的变更单)、处于队列中的工作(如等待QA审核或服务器管理员审核的工单)。
- 额外工序:在交付过程中执行的、并未给客户增值的额外工作,可能包括那些在下游工作中心从没使用过的文档,或是对输出结果做出的并不增值的评审或审批。
- 额外功能:在交付过程中构建的那些组织或客户完全不需要的功能(如“镀金”)。“镀金”:IT项目中无用的面子工程和功能。
- 任务切换:将人员分配到多个项目和价值流里后,他们需要进行上下文切换,并管理工作之间的依赖关系,这会在价值流中耗费额外的工作量和时间。
- 等待:由于资源的竞争而在工作之间产生了等待,这将增加周期时间,延迟了向客户交付价值。
- 移动:信息或数据在工作中心之间移动的工作量。
- 缺陷:由于信息、材料或产品的错误、残缺或模糊,而需要一定的工作量来确认。
- 非标准或手动操作:需要依赖其他人的非标准的或手动的工作,
- 填坑侠:为了实现组织的目标,不得不把有些人和团队置于不太合理的处境,这甚至会成为他们的家常便饭
第二步:反馈原则
在复杂系统中安全地工作
采取以下4项措施让复杂系统更安全地工作:- 管理复杂的工作,从中识别出设计和操作的问题;
- 群策群力解决问题,从而快速地构建新知识;
- 在整个组织中,将区域性的新知识应用到全局范围;
- 领导者要持续培养有以上才能的人。
及时发现问题
群策群力,战胜问题获取新知
只有尽可能在早期阶段,通过全民总动员的方式来解决小问题,才能把灾难性事故消灭在萌芽状态。
事故的发生具有一次性和难追溯性。
在源头保障质量
为下游工作中心而优化
要在问题发生时识别问题,群策群力解决问题并构建新的知识,在源头控制质量,并且不断地为下游工作中心做优化。
第三步:持续学习与实验原则
技术价值流的核心是建立高度信任的文化。
建立学习型组织和安全文化
病态型:病态型组织的特点是组织中存在大量恐惧和威胁。
官僚型:官僚型组织的特点是规则和流程僵化,所有部门通常都“自扫门前雪”。
生机型:生机型组织的特点是积极探索和分享信息,让组织更好地履行使命。
Ron Westrum的组织类型学模型:组织如何处理信息。将日常工作的改进制度化
《精益企业》的作者Mike Orzen说:比日常工作更重要的,是对日常工作的持续改进。把局部发现转化为全局优化
在日常工作中注入弹性模式
通过加压来增强弹性的做法称为抗脆弱性(antifragility)。
在技术价值流中,通过缩短部署的前置时间、提高测试覆盖率、缩短测试执行时间,甚至在必要时解耦架构,都属于在系统中引入类似张力的做法,也都能够提高开发人员的生产效率及可靠性。领导层强化学习文化
领导力的优秀并非体现在做出的所有决定都是对的。相反,更卓越的领导力其实是为团队创造条件,让团队能在日常工作中感受到这种卓越。换句话说,这需要领导者和员工们共同的努力,每个人都相互依存,缺一不可。
开始
选择切入点
绿地项目与棕地项目
软件服务或产品常被分为绿地项目和棕地项目,这两个术语最初用于描述城市规划和建设项目。
绿地项目是指在未开发的土地上建设的项目。
棕地项目则是指在以前用于工业生产的土地上建设的项目,这样的土地可能受到有毒物质或污染物的侵蚀。在技术领域,绿地项目是指全新的软件项目。
DevOps绿地项目通常是指一些试点项目,用于证明公有云或私有云方案的可行性,或者尝试采用自动化部署工具或相关工具等。
DevOps棕地项目是指那些已经服务客户长达几年甚至几十年的产品或服务。兼顾记录型系统和交互型系统
高德纳公司近年来帮助双模IT(bimodal IT)这一概念得到普及。
双模IT指的是企业能够支持各种类型的服务演进。在双模IT中,传统的记录型系统是指类似于ERP的系统(例如MRP系统、人力资源系统、财务报表系统等),它的交易和数据的正确性是至关重要的;
交互型系统则是指面向客户或员工的可交互系统,例如电子商务系统和办公软件。
记录型系统的变化速度通常较慢,并且有监管和合规性要求(例如SOX)。高德纳公司称这种系统为“类型1”,侧重于“做得正确”。
交互型系统的变化速度通常较快,因为它需要快速响应反馈,通过实验找到最能满足客户需求的方式。高德纳公司称这种系统为“类型2”,侧重于“做得快速”。从最乐于创新的团队开始
所谓跨越鸿沟,是指克服困难并找到比创新者和早期采用者更大的群体。扩大DevOps的范围
将大的改进目标分解成渐进式的小步骤。
当推进变革时,如何基于已获得的支持扩大影响:
(1)发现创新者和早期采用者:一开始,把重点放在真正有意愿改进的团队上。
(2)赢得沉默的大多数:在下一阶段,力求将DevOps实践扩展到更多的团队和价值流,目标是建立更稳固的群众基础。
(3)识别“钉子户”:所谓“钉子户”,是指那些高调的、有影响力的反对者。
运用价值流
确定创造客户价值所需的团队
针对团队工作绘制价值流图
组建专门的转型团队
既定的流程属于一种群体意识。专门的转型团队需要创建新的流程,从而得到想要的结果,创造新的群体意识。- 拥有共同的目标
- 保持小跨度的改进计划
- 为非功能性需求预留20%的开发时间,减少技术债务
将20%的时间用于创造用户不可见的正面价值。
缓解员工的技术债务压力也可以降低工作倦怠程度。
Kevin Scott说:不管是个人目标,还是团队目标,都是帮助公司盈利。如果你有机会领导工程师团队,最好从CEO的角度看问题,透彻理解公司、业务、市场、竞争环境需要什么,并将这些理解应用到你的团队中,帮助公司赢得市场。 - 提高工作的可视化程度
用工具强化预期行为
设计组织结构
康威定律
康威提出了著名的康威定律。他指出:系统设计受限于组织自身的沟通结构。组织的规模越大,灵活性就越差,这种现象也就越明显。
《大教堂与集市》的作者Eric S. Raymond在他的“黑客字典”中总结出一个更简单(而且现在更有名)的康威定律“软件的架构和软件团队的结构是一致的。
组织结构决定了工作方式和工作成果。在决策科学领域,主要有3种组织结构类型:职能型、矩阵型和市场型。
- 职能型组织结构注重提高专业技能、优化分工或降低成本。
- 矩阵型组织结构试图结合职能型和市场型。
- 市场型组织结构注重快速响应客户需求。
过度职能导向的危害(“成本优化”)
组建以市场为导向的团队(“速度优化”)
使职能导向有效
组建跨职能和以市场为导向的团队是实现快速流动和可靠性的一种方式。
Mike Rother在《丰田套路》一书中写道:尽管看似诱人,但其实无法通过重组的方式获得持续的改进和适应性。起决定性作用的并不是组织形式,而是人们的行为和反应。丰田成功的根本原因不在于其组织结构,而在于它的发展能力和员工的工作习惯。将测试、运维和信息安全融入日常工作
共同的痛点可以强化团队的共同目标。使团队成员都成为通才
全栈工程师这个术语现在通常是指那些熟悉或至少大致理解整个应用栈(例如代码、数据库、操作系统、网络和云)的通才。
专家、通才与E型人才。
E型人才是指在经验、专业、探索能力和执行能力4个方面都表现突出的人。
投资于服务和产品,而非项目
实现高绩效的另一种方法是组建稳定的服务团队,持续提供资金,让他们执行自己的战略和计划。根据康威定律设定团队边界
创建松耦合架构,提高生产力和安全性
- 面向服务架构(Service-Oriented Architecture, SOA)这一概念在20世纪90年代被提出,它是一种支持独立测试和部署服务的架构方式,其典型特征是由具有限界上下文的松耦合服务组成。
- 松耦合的架构意味着在生产环境中可以独立更新某一项服务,而无需更新其他服务。
- 限界上下文(bounded context)是Eric Evans在《领域驱动设计》一书中提出的概念。其思路是开发人员应该能够理解和更新服务的代码,而不必知道其对等服务的内部逻辑。各服务严格通过API交互,因此不必共享数据结构、数据库模式或对象的其他内部表示。
- 保持小规模(“两个比萨原则”)。
日常运维
将运维融入日常开发工作
3个通用的策略:- 构建自服务能力,帮助开发人员提高生产力;
- 将运维工程师融入服务团队;
- 如果运维工程师人数紧张,则可以采用运维联络人模式。
创建共享服务,提高开发生产力
发现经实践验证的工具并拓展其使用范围,要比从零开始构建这些功能更容易成功。将运维工程师融入服务团队
为每个服务团队分派运维联络人
邀请运维工程师参加开发团队的会议
可视化是将运维工作融入产品价值流的关键。
第一步:流动的技术实践
部署流水线
部署流水线的目标就是能够基于版本控制系统中的信息重复搭建整套生产环境。
按需搭建开发环境、测试环境和生产环境
使用自动化的方式构建和配置环境:- 复制虚拟化环境(如VMware虚拟机镜像、执行Vagrant脚本,以及启动Amazon EC2虚拟机镜像文件);
- 构建“裸金属物理机”的自动化环境搭建流程(例如,使用PXE方式通过基线镜像进行安装);
- 使用“基础设施即代码”的配置管理工具(例如Puppet、Chef、Ansible、SaltStack、CFEngine等);
- 使用操作系统自动化配置工具(例如Solaris Jumpstart、Red Hat Kickstart和Debian preseed);
- 使用一组虚拟镜像或容器(例如Vagrant和Docker)搭建环境;
- 在公有云(例如Amazon Web Services、Google App Engine和Microsoft Azure)、私有云或其他PaaS(平台即服务,如OpenShift和Cloud Foundry等)中创建新环境。
使基础设施的重建更容易
Bill Baker是微软的一名资深工程师。他称我们过去对待服务器就像对待宠物:“我们给它们起名字,并在它们生病时悉心照料。现在,我们对待服务器更像对待牲畜:给它们编号,在它们生病时把它们干掉。”雪花服务器是像雪花那样独一无二的服务器,手动配置的。
凤凰服务器是那些可以销毁重建又不影响业务的服务器,自动配置的。
混沌工程是任意拿掉一个服务器或者引入一个故障点不影响整个系统的使用。运行在类生产环境里才算“完成”
“完成”是指不仅实现了功能正确的代码,而且在每个迭代周期结束时,已经在类生产环境中集成和测试了可工作和可交付的代码。
自动化测试
实现快速可靠的自动化测试
Mike Bland在描述部署变更的开发人员时说道:“恐惧是心灵杀手。它使新手不敢变更,因为他们不了解系统。它也使老手不敢变更,因为他们太了解系统。”创建自动化测试套件的目的是提高集成频率,使测试从阶段性活动演变成持续性活动。
开发过程中的持续集成(continuous integration, CI)通常是指将多个代码分支持续集成到主干中,并确保它们都会通过单元测试。然而,在持续交付和DevOps中,持续集成还要求在类生产环境中运行应用,并且通过集成测试和验收测试。Jez Humble和David Farley为了消除歧义,称后者为CI+。
正确的持续集成实践总是可以确保代码处于可部署和可交付的状态。目前存在各种各样的部署流水线工具,其中许多是开源软件(例如Jenkins、ThoughtWorks GoCD、Concourse、Bamboo、Microsoft Team Foundation Server、TeamCity和GitLab CI,以及基于云的解决方案,例如Travis CI和Snap)。
构建快速可靠的自动化测试套件
自动化测试从快到慢分为如下几类:- 单元测试:通常独立测试每个方法、类或函数。它的目的是确保代码按照开发人员的设计运行。由于诸多原因(如需要进行快速和无状态的测试),通常会使用打桩(stub out)的方式,隔离数据库和其他外部依赖
- 验收测试:通常整体测试应用,确保各个功能模块按照设计正常工作(例如符合用户故事的业务验收标准,API能正确调用),而且没有引入回归错误(即没有破坏以前正常的功能)。
- 集成测试:保证应用能与生产环境中的其他应用和服务正确地交互,而不再调用打桩的接口。
单元测试的目的是证明应用的某一部分符合程序员的预期……验收测试的目的则是证明应用能满足客户的愿望,而不仅仅是符合程序员的预期。
最快速的测试应该尽可能多地发现错误。
自动化测试的目的是尽可能多地发现代码错误,并且减少对手动测试的依赖。
编写和执行自动化性能测试的目标是验证整个应用栈(代码、数据库、存储、网络、虚拟化等)的性能,并把它作为部署流水线的一部分,这样才能尽早发现问题,并以最低的成本和最快的速度解决问题。在部署流水线失败时拉下安灯绳
每个人都知道工作不只是‘编写代码’,更是‘运行服务’。
瀑布式Scrum反模式(water-Scrum-fall anti-pattern):表面上采用敏捷开发实践,但实际上,所有测试和缺陷修复仍然在项目快结束时才进行。
持续集成
基于主干的开发方式能带来更高的生产力、更好的稳定性,甚至更高的工作满意度和更低的职业倦怠率。
每日提交代码,也迫使开发人员进一步分解工作,同时保持主干处于可发布状态。
提交之后需要合并到主分支吗?今天的代码功能写了一半也得提交?加了个空行也可以提交吗?增加过多的提交记录是否有意义?觉得每日提交需要探讨可行性,按功能特性提交是否可以,大的就拆分成小的
自动化发布
要求代码的部署操作是自动化、可重复和可预测的。
按需地(即一键式发布)或自动化地(即在构建和测试成功以后,直接进行自动化部署)。
自动化部署流程
当完整记录目前的部署流程以后,下一步的目标便是尽可能地简化和自动化手动步骤:- 将代码打包成便于部署的格式;
- 创建预配置的虚拟机镜像或容器;
- 将中间件的部署和配置自动化;
- 将安装包或者文件复制到生产服务器;
- 重启服务器、应用或者服务;
- 基于模板生成配置文件;
- 通过执行自动化冒烟测试,确保系统能正常运行,并且配置正确;
- 运行各种测试程序;
- 将数据库迁移工作脚本化和自动化。
部署流水线的需求:
- 用相同的方式处理所有环境的部署:
- 对部署执行冒烟测试:
- 维持环境的一致性:
代码发布流程:
- 构建
- 测试
- 部署
高绩效组织的部署交付周期以分钟或小时为单位,而低绩效组织则以月为单位。
将部署与发布解耦
部署是指在特定的环境中安装指定版本的软件(例如,将代码部署到集成测试环境中或生产环境中)。具体地说,部署可能与某个特性的发布相关,也可能无关。
发布是指把一个特性(或者一组特性)提供给所有客户或者一部分客户(例如,向5%的客户群开放特性)。代码和环境架构要能够满足这种要求:特性发布不需要变更应用的代码。通常使用的发布模式有以下两种:
基于环境的发布模式:将新的代码部署到非生产环境中,然后再把生产流量切换到这个环境。
包括蓝绿部署、金丝雀发布和集群免疫系统。基于应用的发布模式:对应用进行修改,从而通过细微的配置变更,选择性地发布或开放应用特性。
包括黑启动技术(灰度发布)。基于应用的发布模式更安全:
- 实现特性开关
特性开关的优势:轻松地回滚;缓解性能压力;采用面向服务架构提高恢复能力。 - 实现黑启动
- 实现特性开关
持续交付
Eugene Letuchy:在一夜之间把用户量从零涨到7000万的秘诀就是,千万别想一步登天。
Jez Humble:我们不应该关注形式,而应该关注结果:部署应该是低风险、按需进行的一键式操作。持续交付是指,所有开发人员都在主干上进行小批量工作,或者在短时间存在的特性分支上工作,并且定期向主干合并,同时始终让主干保持可发布状态,并能做到在正常的工作时段里按需进行一键式发布。开发人员在引入任何回归错误时(包括缺陷、性能问题、安全问题、可用性问题等),都能快速得到反馈。一旦发现这类问题,就立即加以解决,从而保持主干始终处于可部署状态。
持续部署是指,在持续交付的基础上,由开发人员或运维人员自助式地定期向生产环境部署优质的构建版本,这通常意味着每天每人至少做一次生产环境部署,甚至每当开发人员提交代码变更时,就触发一次自动化部署。持续交付是持续部署的前提条件,就像持续集成是持续交付的前提条件一样。
持续集成 -> 持续交付 -> 持续部署
演进式架构
演进式架构原则,正如Jez Humble所说:任何成功的产品或公司,其架构都必须在生命周期里不断演进。
在很大程度上,服务赖以生存的架构决定了代码的测试和部署方式。
架构是影响工程师生产力的首要因素,它还决定了是否能快速和安全地实施变更。
经验1:严格遵从面向服务理念的架构设计能完美地实现隔离,从而达到前所未有的掌控水平。
经验2:禁止客户端直接访问数据库,使在不涉及客户端的情况下提高服务状态的可扩展性和可靠性成为可能。
经验3:在切换到面向服务的架构后,开发和运维流程将受益匪浅。服务模式进一步强化了以客户为中心的团队理念。每个服务都有一个与之对应的团队,该团队对服务全面负责(从功能规划到架构设计、构建和运维)。
第二步:反馈的技术实践
遥测系统
遥测被广泛定义为“一个自动化的通信过程,先在远程采集点上收集度量数据,然后传输给与之对应的接收端用于监控。
Etsy的工程师Ian Malpass:跟踪一切是快速行动的关键,但能毫不费力地跟踪一切是唯一的途径。
建设集中式监控架构
在《The Art of Monitoring》书中,James Turnbull描述了一种现代的监测体系架构:
在业务逻辑、应用程序和环境层收集数据:在每一层中,建立以事件、日志和指标为对象的监控。
负责存储和转发事件和指标的事件路由器:此功能支持监控可视化、趋势分析、告警、异常检测等。建立生产环境的应用程序日志遥测
使用遥测指导问题的解决
平均清白证明时间(即花多长时间说服其他人,不是我们造成了中断)。将建立生产遥测融入日常工作
建立自助访问的遥测和信息辐射器
信息辐射器(information radiator),是由敏捷联盟定义的:这个通用术语指的是,团队放置在一个非常显眼位置上的手写、绘制、印刷或电子信息展示,让所有团队成员以及路过的人都可以快速浏览最新信息:自动化测试次数、速率、事故报告、持续集成状态等。这个想法起源于丰田生产系统。发现和填补遥测的盲区
需要以下层级的度量指标:- 业务级别
- 应用程序级别
- 基础架构级别(如数据库、操作系统、网络、存储)
- 客户端软件级别(如客户端浏览器上的JavaScript、移动应用程序)
- 部署流水线级别

遥测数据
DevOps运动的早期领导者John Vincent指出:现在告警疲劳是我们面临的最大问题……我们需要更智能的告警,否则大家都要疯掉了。
用均值和标准差识别潜在问题
标准差的常见用途是,定期检查数据集的某个度量,如果与均值有显著差异就告警。异常状态的处理和告
非高斯分布遥测数据的问题
其消费者的浏览模式有着惊人的一致性和可预测性,尽管未呈高斯分布。应用异常检测技术
异常检测,其通常的定义是“搜索不符合预期模式的数据条目或事件”。
平滑技术通常涉及使用移动平均数(或滚动平均数),它利用每个点与滑动窗口中的所有其他数据的平均值,来转换数据。
还有一些更奇特的过滤技术,诸如快速傅里叶变换和Kolmogorov-Smirnov检验(Graphite和Grafana工具内嵌),其中前者广泛应用于图像处理,后者经常用于分析周期性/季节性度量数据的相似性或差异性。
安全部署
对生产环境的变更越小,遇到的问题就越少。
通过遥测使部署更安全
迅速恢复服务。通过这种方式,并结合所需的架构,我们“优化了平均恢复时间,而不是平均故障间隔时间”。这是一条流行的DevOps准则,它强调的是持续提升从故障中快速恢复的能力,而不是企图避免发生故障。开发和运维共同承担值班工作
让开发人员跟踪工作对下游的影响
交互和用户体验设计中最强大的技术之一是情境访谈。让开发人员自行管理生产服务
服务发布指南和要求可能包括以下内容:- 缺陷计数和严重性:应用程序是按设计运行的吗?
- 告警的类型/频率:在生产环境中应用程序所产生的告警数量是否太多,无法得到支持?
- 监控覆盖率:监控覆盖的范围是否够大,能够为恢复故障服务提供足够的信息?
- 系统架构:服务松耦合的程度是否足以支持生产环境中高频率的变更和部署?
- 部署过程:在生产环境中代码部署的过程是不是可预测的、确定性的和足够自动化的?
- 生产环境的整洁:是否有迹象表明生产习惯已经足够好,可以让其他任何人提供生产支持?
服务回传机制。当生产环境中的一个服务变得非常脆弱时,运维部门能把支持这个服务的责任交回给开发部门。
站点可靠性工程师(Site Reliability Engineer, SRE),是软件开发工程师负责了以前所说的运维工作。
A/B测试
Jez Humble指出:验证业务模式或产品理念的最低效的方法,是构建完整的产品以查看设想中的需求是否真实存在。
A/B测试技术是在直效营销中率先使用的,它是两大类营销策略之一。另一类称为大众营销或品牌营销,通常通过向公众投放尽可能多的广告来影响人们的购买决策。
在功能测试中集成A/B测试
在现代用户体验实践中,最常用的A/B测试技术是,在一个网站上,给访问者随机地展示一个页面的两个版本之一,即控制组(A)或实验组(B)。基于对这两组用户后续行为的统计分析,可以判断这两者的结果是否存在显著差异,从而找出实验组(例如,功能的变化、设计元素、背景颜色)和结果(例如,转化率、平均订单大小)之间的因果联系。
A/B测试也称为在线控制实验和拆分测试。在实验的过程中还支持多个变量,从而观察变量之间的相互作用,这种技术称为多变量测试。在发布中集成A/B测试
在功能规划中集成A/B测试
Stoneham发现,就像产品经理和开发人员谈论指标驱动一样,如果不能频繁地(每天或每周)进行实验,日常工作的重点就只能放在功能开发而不是客户成果上了。
评审流程
Giray Özil在Twitter上所说:请程序员来审查10行代码,他会找到10个问题。请他审查500行代码,他会说看起来都不错。
反事实思维是心理学术语,指人们往往针对已经发生的生活事件创建其他可能的叙述。在可靠性工程中,反事实思维通常涉及对“想象中系统”而非“现实系统”的叙述。
丰田生产系统的核心理念之一是“最了解问题的人通常是离问题最近的人”。
绩效组织更多地依赖同行评审,更少地依赖外部变更批准。
与在部署之前需要外部组织的审批不同,同行评审是要求工程师请同行对他们的变更进行评审。在开发中,这种实践被称为代码评审,但它同样适用于对应用程序或环境(包括服务器、网络和数据库)进行的任何变更。注5同行评审的目标是通过工程师同事的仔细核查来减少变更错误。
代码评审有如下几种形式:
- 结对编程:程序员结对地在一起工作。
- “肩并肩”:在一名程序员编写了一段代码后,评审程序员接着就逐行阅读他的代码。
- 电子邮件送审:在代码被签入到代码管理系统中后,系统就立刻自动向评审者们邮寄一份代码。
- 工具辅助评审:编码者和审阅者都使用专门用于代码评审的工具(例如,Gerrit、GitHub的Pull Request等)或由源代码仓库(例如,GitHub、Mercurial、Subversion,以及Gerrit、Atlassian Stash和Atlassian Crucible等其他平台)提供的类似功能。
Elisabeth Hendrickson是Pivotal软件公司的工程副总裁,也是《探索吧!深入理解探索式软件测试》一书的作者。她广泛地发表的观点是:每个团队都应该对自己的质量负责,而不是让单独的部门来负责。
第三步:持续学习与实验的技术实践
日常学习
Peter Senge:组织唯一的可持续竞争优势就是比对手更快的学习能力。
建立公正和学习的文化
Sidney Dekker博士将这种通过消除肇事者而消除错误的观念叫作坏苹果理论。他断言这是无效的,因为“人为错误并不是问题的原因;恰恰相反,人为错误是我们提供的工具存在设计问题而造成的后果”。有两个有效的实践有助于创造公正的学习型文化:一是不指责的事后分析;二是在生产环境中引入受控的人为故障,用于创造机会针对复杂系统中不可避免的问题进行练习。
举行不指责的事后分析会议
不指责的事后分析,这种做法也称为对事不对人的事后分析或者事后反思。
必须关注细节的记录并强化这样一种文化:信息是能够分享的,不必害怕因此受到惩罚或报复。
这些应对措施的范例包括:新增能检测部署流水线异常状况的自动化测试,添加更深入的生产环境遥测指标,识别需要额外同行评审的变更类型,以及在定期的演练日里进行针对此类故障的演习。尽可能广泛地公开事后分析会议结果
降低事故容忍度,寻找更弱的故障信号
我们所做的全部工作都是潜在的重要假设和数据来源,而不是重复的例行公事或对过去实践的验证。重新定义失败,鼓励评估风险
在生产环境注入故障来恢复和学习
主动关注可恢复性意味着公司能够以常规、平常的方式处理可能在大多数组织里引发危机的事件。创建故障演练日(Game Day)
不指责的事后分析会议和在生产环境中注入故障都强化了这样一种文化:每个人都应该坦然面对失败,承担责任,并从失败中学习。
全局经验
Randy Shoup:防止谷歌发生故障的最强大机制就是单一代码库。
使用聊天室和聊天机器人自动积累组织知识
GitHub的Hubot能够触发各种自动化工具,包括Puppet、Capistrano、Jenkins、Resque(一个Redis维护的、创建后台作业队列的库)和GraphMe(从Graphite生成图形)。软件中便于重用的自动化、标准化流程
与其将专业知识写到Word文档中,倒不如将完整包含组织学习和知识的各种标准和流程转化为一种便于执行的形式,使之更容易重用。
实现知识重用的一种好方法是:将其保存在集中的源代码库里,使之成为所有人都可以搜索和使用的工具。创建全组织共享的单一源代码库
运用自动化测试记录和交流实践来传播知识
通过确定非功能性需求来设计运维
把可重用的运维用户故事纳入开发
确保技术选型有助于实现组织目标
Tom Limoncelli说过:“我在谷歌工作时,有一个官方编译语言、一个官方脚本语言和一个官方用户界面(UI)语言。是的,尽管也可以通过某些方式支持其他语言,但坚持这“三大语言”意味着支持程序库、工具,以及更便于找到合作者的方式。”作者注:谷歌使用C++作为官方编译语言,使用Python(后来是Go)作为官方脚本语言,并使用Java和JavaScript(通过Google Web Toolkit)作为官方UI语言。
我们通过主动和广泛地传播新知识来实现这个目标,例如采用聊天室、架构即代码、共享源代码库、技术标准化等方法。
预留时间
偿还技术债务的制度化惯例
有一种称作改善闪电战(improvement blitz或kaizen blitz)的实践,是丰田生产系统的重要组成部分,指的是在一个专门集中的时间段里解决特定问题,通常长达几天。
除了源于精益的术语“改善闪电战”之外,为改进工作而专门实行的惯例还有春季/秋季大扫除、记票队列反转周。其他术语还包括黑客日、黑客马拉松和20%的创新时间等。让所有人教学相长
在DevOps会议中分享经验
传播实践的内部顾问和教练
测试认证(TC)提供了改进自动化测试实践的路线图。正如Bland所描述的那样,“它旨在发扬谷歌文化中优先关注度量指标的特点……同时克服无从下手的心理恐惧。第1级是快速建立基准度量指标,第2级是设置配套策略并达到自动化测试的覆盖率目标,第3级是努力实现长期的覆盖率目标”。帮助强化终身学习以及重视在日常工作中改进日常工作的文化。具体实现方法是:预留偿还技术债务的时间;创建论坛,使大家能够在组织内部和外部互相学习和指导;通过辅导、咨询,或者仅仅设置一段面谈时间,让专家能够为内部团队提供帮助。
当我们在复杂系统中工作时,从事故中学习,创建共享代码库和共享知识是必不可少的。
集成的技术实践
信息安全
将安全集成到开发迭代的演示中
GE资本美洲公司企业架构(EA)前首席信息官Snehal Antani曾说,他们的三大关键业务衡量标准是“开发速度(即向市场提供功能的速度)、客户交互的故障(即服务中断、报错)和合规响应时间(即从审计提出请求到提供所有必需的定量和定性信息的时间)”。将安全集成到缺陷跟踪和事后分析会议中
将预防性安全控制集成到共享源代码库及共享服务中
将安全集成到部署流水线中
保证应用程序的安全性
开发阶段的测试关注功能的正确性,着眼点是正确的逻辑流程。这种类型的测试通常称为愉快路径(happy path),它验证的是用户的正常操作流程(有时候存在几个可选的路径)——一切都按预期执行,没有例外或出错状况。
QA人员、信息安全人员和欺诈者其实经常关注不愉快路径(sad path),它在事情出错时发生,尤其与安全相关的错误状况有关。(这类安全特定状况常被戏称为坏路径。)期望包含以下内容作为测试的一部分:
- 静态分析:这是在非运行时环境中执行的测试,期望在部署流水线中进行。通常,静态分析工具将检查程序代码所有可能的运行时行为,并查找编码缺陷、后门和潜在的恶意代码(有时称为“从内向外测试”)。此类工具包括Brakeman、Code Climate和搜索禁止代码功能(例如,exec())。
- 动态分析:与静态测试相反,动态分析由一系列在程序运行时执行的测试组成。动态测试监视诸如系统内存、功能行为、响应时间和系统整体性能等项目。这种方法(有时称为“从外向内测试”)就好像有恶意的第三方与应用程序交互。此类工具包括Arachni和OWASP ZAP(Zed攻击代理)。
- 依赖组件扫描:这是另一种静态测试,通常于构建时在部署流水线里执行。它会清点二进制文件和可执行文件依赖的所有包和库,并确保这些依赖组件(我们通常无法控制)没有漏洞或恶意二进制文件。Ruby的Gemnasium和bundler审核,Java的Maven以及OWASP依赖性检查就是其中的几个例子。
- 源代码完整性和代码签名:所有开发人员都应该有自己的PGP密钥,可以在诸如keybase.io之类的系统中创建和管理。向版本控制系统中提交的一切都应该签名——使用开放源代码工具gpg和git直接配置。
确保软件供应链的安全
有助于确保软件依赖完整性的工具包括OWASP依赖性检查和Sonatype Nexus Lifecycle。确保环境的安全
将信息安全集成到生产环境遥测中
在应用程序中建立安全遥测系统
在环境中建立安全遥测系统
保护部署流水线
安全合规
将安全和合规性集成到变更批准流程中
ITIL定义了这些流程,将变更分为如下3种类型:- 标准变更:遵循既定批准流程的低风险变更,但也可以是预批准的。
- 常规变更:风险更高、需要权威机构评审或批准的变更。
- 紧急变更:在紧急情况下必须立即投入生产环境的变更(例如,紧急安全补丁、恢复服务),属于潜在的高风险变更。
将大量低风险变更重新归类为标准变更
如何处理常规变更
破坏性测试。这是制造业的术语,指的是在最严酷的操作条件下执行长时间的耐久性测试,直到摧毁测试部件。减少对职责分离的依赖
在可能的情况下,应避免使用职责分离作为控制手段。我们应该选择结对编程、持续检查代码签入和代码审查等,它们能为工作质量提供必要的保障。确保为审计人员和合规人员留存文档和证据
附录
在制品指按客户订单生产的但还不能立即发货的产品。
精益的两个主要原则是:
(1)坚信前置时间(把原材料转换为成品所需的时间)是提升质量、客户满意度和员工幸福感的最佳预测指标;
(2)小批量尺寸是短前置时间的一个最佳预测指标,理论上讲最理想的批量尺寸是“单件流”(即“1×1”的流,库存为1,批量尺寸为1)。
误区与真相之间的区别:
| 误区 | 真相 |
|---|---|
| 人为错误被视为事故原因 | 人为错误被视为组织内更深层次的系统性漏洞的后果 |
| 陈述“人们当时应该怎么做”就是对失败的最好总结 | “人们当时应该怎么做”并不能解释“为什么他们觉得当时那么做是合理的” |
| 告诉人们更加小心就可以消除问题 | 只有不断寻找组织的漏洞,才能提高安全性 |
CI/CD是一种软件开发流程模型,旨在通过自动化和持续性的构建、测试、部署和交付过程,来提高软件开发和发布的效率和质量。
CI/CD的目标是缩短软件开发和发布的周期,降低开发和发布的成本和风险,以满足快速变化和不断迭代的业务需求。
通常,CI/CD包括以下几个环节:
- 持续集成(Continuous Integration,CI):开发人员将代码不断地提交到源代码管理系统中,该过程中,自动化的测试和构建工具会自动从源代码库中获取最新的代码,进行编译、测试、打包等操作,并生成相应的构建产物。
- 持续交付(Continuous Delivery,CD):将构建产物部署到测试环境,进行测试和验证,最终生成可部署的产物。
持续交付的理念,其中包括确保将代码和基础设施始终处于可部署状态的“部署流水线”,并且确保所有提交到主干的代码都能安全地部署到生产环境里。 - 持续部署(Continuous Deployment,CD):将构建产物部署到生产环境,实现自动化的部署和发布,从而实现快速的交付和迭代。
持续集成(提交代码,构建,自动化测试)-> 持续交付(部署到测试环境)-> 持续部署(部署到生产环境)
DevOps是“开发”和“运维”这两个词的缩写。DevOps是一套最佳实践方法论,旨在在应用和服务的生命周期中促进IT专业人员(开发人员、运维人员和支持人员)之间的协作和交流,最终实现:
- 持续集成——每天数次将所有开发工作副本并入共享主线;
- 持续部署——持续发布,或尽可能经常地发布;
- 持续反馈——在生命周期的各个阶段寻求来自利益干系人的反馈。
DevOps实践源自三步工作法:
- 第一步是从开发到运维再到客户,实现从左到右快速流动;
- 第二步是从所有利益干系人到价值流,实现从右到左快速反馈;
- 第三步是通过创建高度信任的实验和风险承担文化,促进学习。
点评:比起故事性的渐进式引人入胜,叙述性的方法论总是需要耐心需要时间进入状态。
理论很丰满,实践出真知。
DevOps入门与实践
[日] DevOps引入指南研究会
认识DevOps
背景
DevOps指的是通过Dev(开发)和Ops(运维)的紧密合作来提高商业价值的工作方式和文化。
瀑布模型中划分了明显的开发阶段,在一个开发阶段没有结束之前就不能开始下一个阶段的工作。
原型法是一边运营服务一边汲取服务反馈的方法。
敏捷开发是指以小规模团队为前提,每次只发布最低限度的功能集,然后听取客户的反馈,进行持续改善。
基础设施即代码(Infrastructure is code)/ 基础设施代码化,是由对服务器、存储和网络等基础设施进行配置的provisioning(服务提供)工具发展而来的。
provisioning工具的三层:
| 层 | 说明 | 相关工具 |
|---|---|---|
| 编排 | 负责部署或者节点之间的集群管理等,对多个服务器进行设置和管理 | Capistrano、Func |
| 配置管理 | 对操作系统或者中间件进行设置 | SmartFrog、CFEngine |
| 引导 | 创建虚拟机、安装操作系统等 | Kickstart、Cobbler |
用Ansible等配置管理工具,可以得到以下好处:
- 省时省力:通过自动化进行快速设置
- 声明式:通过配置信息可以对当前配置对象的具体状态进行明确描述
- 抽象化:不需要根据细微的环境差异分开描述配置信息,尽量消除代码执行的专业性
- 收敛性:不管对象的状态如何,最终都会达到期望的状态
- 幂等性:不管执行多少次,都能得到相同的结果
用于应对变化的工具:
- Automated infrastructure(基础设施自动化)
- Shared version control(版本管理共享)
- One step build and deploy(一步式构建和部署)
- Feature flags(通过配置项来管理应用中的某一功能是有效还是无效)
- Shared metrics(共享指标数据)
- IRC and IM robots(互联网中继聊天、即时通信机器人)
用于应对变化的文化:
- Respect(尊重)
- Trust(信任)
- Healthy attitude about failure(正确认识失败)
- Avoiding Blame(避免指责)
认识
PDCA循环
PDCA循环是现代质量管理之父爱德华兹·戴明(Edwards Deming)提出的一种管理方法,主要用于在企业活动或商业活动中进行持续的生产改善和采取相应的控制措施。这一方法将业务分为Plan(计划)→Do(执行)→ Check(检查)→ Act(处理)四个阶段。
支持开发和运维紧密合作的工具所具备的要素:
抽象化
抽象化是指对所有资源进行抽象,消除不同平台之间的差异,降低专业难度和复杂度。进一步对抽象化进行分解,可以得到两层含义:
一个是“标准化”,即可以用相同的标准或者规则对一个或多个不同的程序和设备进行调用;
一个是“虚拟化”,即伪装成实际并不存在的事物。基础设施的抽象化包括对操作系统、服务器、存储和网络等的抽象:
- 操作系统的抽象化
2008年,Linux操作系统中出现了LXC(Linux Containers),它通过命名空间技术以独立进程为单位实现资源隔离。
2013年dotCloud公司(现已更名为Docker公司)开源了使用LXC实现的容器技术Docker。 - 物理服务器的抽象化
虚拟化的硬件被称为虚拟机,而作为虚拟机运行载体的操作系统被称为Hypervisor。Hypervisor有两种实现方式:
一种是在安装完Linux或者Windows等操作系统之后,将Hypervisor软件安装在操作系统中;
另一种是直接在物理硬件上安装Hypervisor软件(也称为Bare Metal Hypervisor方式)。 - 存储的抽象化
可以在一台物理存储设备上创建多个逻辑存储设备,或者可以根据具体的策略决定操作内容以及进行内容分发的存储设备,称为SDS(Software Defined Storage,软件定义存储)。 - 网络的抽象化
SDN(Software Defined Network,软件定义网络)有几种实现方式,这些实现方式的共同点就是将交换机分成Control Plane(配置等管理功能)和Data Plane(数据包转发功能)两个层面。
- 操作系统的抽象化
自动化
自动化是指不需要人为操作,由程序来机械地进行控制的过程。通过自动化的方式使用抽象化的资源,降低专业难度,减小开发、运维人员的工作压力。
统一管理
信息的统一和可视化是开发和运维紧密合作不可欠缺的要素。通过统一的版本管理系统和沟通工具使信息可视化,构建开发和运维之间紧密的关系。
- 问题跟踪系统(Issue Tracking System, ITS)/ ticket管理工具
比较知名的包括JIRA、Redmine和Trac等。
ticket驱动开发的方法,该方法提倡无论是提交应用程序还是基础设施的代码,所有的任务都需要先创建一个ticket,然后再开始工作。 - 设计文档和平日会议记录
这种方式的代表工具有Redmine的Wiki和Confluence。 - 沟通工具
早前的沟通工具有IRC,现在比较有代表性的工具是Skype、Slack和ChatWork等,
- 问题跟踪系统(Issue Tracking System, ITS)/ ticket管理工具
软件配置管理工具(Software Configuration Management, SCM)
软件配置管理工具也包含了支持版本管理和发布管理等功能的系统,其中版本管理工具有Git、Subversion和Perforce等。持续集成
持续集成(Continuous Integration, CI)是指频繁并持续地实施代码构建和静态测试、动态测试等工作。
开源的持续集成工具,如Jenkins。通过统一开发部门和运维部门的开发及构建方法,大幅提升系统改善的速度。
监控
对资源信息进行集中管理和可视化,构建开发和运维的紧密合作关系
支持开发和运维紧密合作的文化所具备的要素:
- 目的意识
如果开发和运维有相同的目标,即共同创造服务、迅速满足商业需求,则更容易实现紧密合作。 - 同理心
开发和运维团队互相考虑对方的感受,接受对方,建立紧密的关系。 - 自主思考
开发部门和运维部门不互相依赖,能自主开展工作,以此来不断接近共同目标。
组织
滚动更新(rolling update)是一种更新升级方式,是指在由多个组件构成的系统中,每次只更新其中的一部分组件,从而在不停止系统的前提下实现整个系统的更新。
康威定律的大意为:设计系统的组织,其产生的设计等同于组织的沟通结构。
实践DevOps
准备环境
使用工具并不是DevOps的目的,但是如果使用工具可以提高开发和运维的效率,促使运维人员和开发人员紧密合作,迅速满足商业活动的需求,那么就也可以算作实现DevOps的一种手段。
正因为是重复性工作,所以提高这类工作的效率很容易取得非常明显的效果。
系统开发和运维的流程大体来说都包含以下几个阶段:
- 计划和需求分析
- 设计和实现
- 测试
- 发布
- 运维
Vagrant | 环境代码化
使用Vagrant实现本地开发环境的代码化。
Ansible | 构建通用化
使用Ansible将构建工作通用化。
声明式,就是指通过配置信息来明确描述配置对象的状态,并管理这个状态。德哈恩将配置管理工具称为声明式语言。
声明式侧重于描述希望服务器进入的状态,而不是描述希望服务器如何进行处理。
配置管理信息在Ansible中称为Playbook,在Puppet中称为Manifest,在Chef中称为Cookbook。
抽象化是指不需要根据配置对象所在的环境的细微差别而分开编写配置信息,尽量消除代码执行时的专业性。
收敛性是不管对象的状态如何,最终都会变为指定的期望状态。
幂等性是无论执行多少次都能得到相同结果的特性。
通过声明式的方式来定义具备收敛性的状态,并且满足幂等性。
要用Ansible实现的目标有以下3个:
- 使用统一的格式来描述环境的配置信息和构建步骤
- 管理依赖于环境的参数
- 在运行前确认将要变更的地方
定义操作对象:playbook和Inventory文件
定义操作内容:playbook和角色
运行前对变更内容进行确认:dry-run模式
Ansible提供了一个被称为dry-run模式的运行选项。在这种模式下,Ansible不会真正地在实际环境中执行更新操作,而是事先显示在实际执行时哪些地方会被修改。
以dry-run模式运行ansible-playbook命令:
# --check选项表示该命令会以dry-run模式运行
# --diff选项用于显示详细的变更内容
$ ansible-playbook -i development site.yml --check --diffAnsible运行结果的含义:
| 运行结果 | 含义 |
|---|---|
| ok | 对象状态已经和期望的状态相同(即不需要执行任何操作,所以并没有运行) |
| skip | 根据一些具体条件,该任务被忽略(没有被执行)。比如事先在Ansible中设置了任务1执行成功的话就不再执行任务2,这种情况下任务2就不会被执行 |
| changed | 通过执行该任务,对象进入到期望的状态 |
| unreachable | 不能连接到操作对象服务器 |
| failed | 虽然能连接到操作对象服务器,但操作因某种原因而失败(错误) |
Ansible的的功能:
- Tag
只执行指定的任务。 - Dynamic Inventory
可以从外部动态读取Inventory(主机列表)。 - Ansible Galaxy
不必从零开始编写角色,直接从互联网上获取并使用即可。 - Ansible Tower
这是Red Hat公司开发的一款工具,提供了用于Web浏览器的仪表盘以及通过REST API对Ansible进行操作的功能。
基础设施配置管理工具:
Ansible
Ansible是使用Python语言编写的配置管理工具,由Red Hat公司提供。
Ansible主要有以下几个特点:- agentless
不需要事先在配置对象的服务器中安装agent,因此实施起来比较容易。 - YAML格式的配置文件
使用YAML语法定义基础设施配置信息,即使是不擅长编写代码的人也很容易上手。 - 安装简单
只需要安装一个软件包即可,配置管理入门简单。
- agentless
Chef
Chef是一款使用Ruby和Erlang语言编写的配置管理工具,由Chef Software公司提供。
Chef的前身为Chef-Solo。在日本,正是得益于Chef-Solo,基础设施配置管理才逐渐普及。
一般来说,Chef跟Ansible一样,从配置管理服务器上对配置对象服务器进行配置管理,不过它也可以使用Chef-Client的本地模式,只对本机进行配置管理。因此,在不需要进行大规模的基础设施配置管理的情况下,可以使用Chef。
另外,Chef的配置文件采用的是以Ruby为基础的DSL语法,因此可以达到灵活编写配置信息的效果。Itamae
Itamae是由Cookpad公司的荒井良太开发的一款非常简单、轻量的基础设施配置管理工具。
该工具设计的初衷是融合Ansible简单的特性和Chef灵活的DSL语法,成为一款使用起来非常方便的工具。要使用Chef,就必须理解各种各样的术语和配置,所以开始基础设施配置管理的门槛较高,让人望而却步。因此,现在越来越多的公司在积极引入Itamae。
Itamae具有如下特点:- 和Chef相比,需要管理的元素和掌握的术语较少
- agentless
- 独立的插件机制
Puppet
Puppet诞生于2005年,是这几个配置管理工具中出现较早的一个。
Puppet是由Puppet Labs公司采用Ruby语言开发的,但是和Chef不同,它需要采用独自的DSL语法来描述基础设施配置信息,因此被认为使用门槛较高。
与其他配置管理工具不同,Puppet采用pull模式,即从配置对象服务器发起处理。
Serverspec | 基础设施测试代码化
使用Serverspec实现基础设施测试代码化。
在构建之后立刻进行测试,并尽可能地提高一系列工作的效率,这样的实践方式称为持续集成。
Serverspec测试代码中从describe到end之间的部分,是以被称为resource的测试对象为单位进行组织的。其中,it或its指定要执行的测试用例。
使用coderay输出HTML格式的测试报告:$ rake spec SPEC_OPTS="--format html" > ~/result.html
基础设施配置相关的测试工具:
- Test Kitchen
该工具可以对Chef的Cookbook和Ansible的playbook等多种基础设施配置管理工具的代码进行集成测试。 - Kirby
该工具可以统计Ansible的代码覆盖率。 - AnsibleSpec
一个和Ansible组合起来使用的工具,具体来说就是综合了Ansible在远程连接时使用的SSH配置和Serverspec在远程连接时的方法,但测试本身和Serverspec相同。
Git | 共享配置信息
使用Git在团队内共享配置信息。
Vagrant的Vagrantfile、Ansible的playbook和Serverspec的spec文件。
Git的本地仓库分为3个区,分别是工作区(working directory)、暂存区(staging area)和版本库(repository)。
Git客户端(对Git进行操作的工具)可供选择,比如面向Windows用户的Git for Windows、可以进行图形化操作的TortoiseGit和SourceTree等。
在DevOps的世界中,代码是构建步骤,是配置参数,也是测试设计文档。
DevOps的目标
正如DevOps的定义所示,其目标在于通过开发和运维的紧密合作来提高商业价值,只有团队成员共同参与合作,才能发挥出更大的效果。
普及DevOps
意义
在团队内实施DevOps的意义:
- 提高团队开发和沟通的效率:GitHub
- 更简单地进行本地开发环境的创建及共享:Docker
- 使工作程序化(定型化)并进行历史记录管理:Jenkins
- 通过持续工作来提高效率:持续集成(CI)和持续交付(CD)
效率化
使用GitHub进行团队开发
使用Docker提高开发效率
共享环境的方法大致分为两种:一种是共享Vagrantfile或者Ansible的Playbook等配置文件;另一种是直接共享虚拟机镜像。容器技术Docker的优点:
- 启动速度更快
- 资源使用效率更高
- 开发环境共享更加方便
Docker Compose通过在YAML格式的配置文件中描述容器信息来批量启动多个容器。Docker Compose只是一个单一的执行文件。
Docker for Mac/Windows:
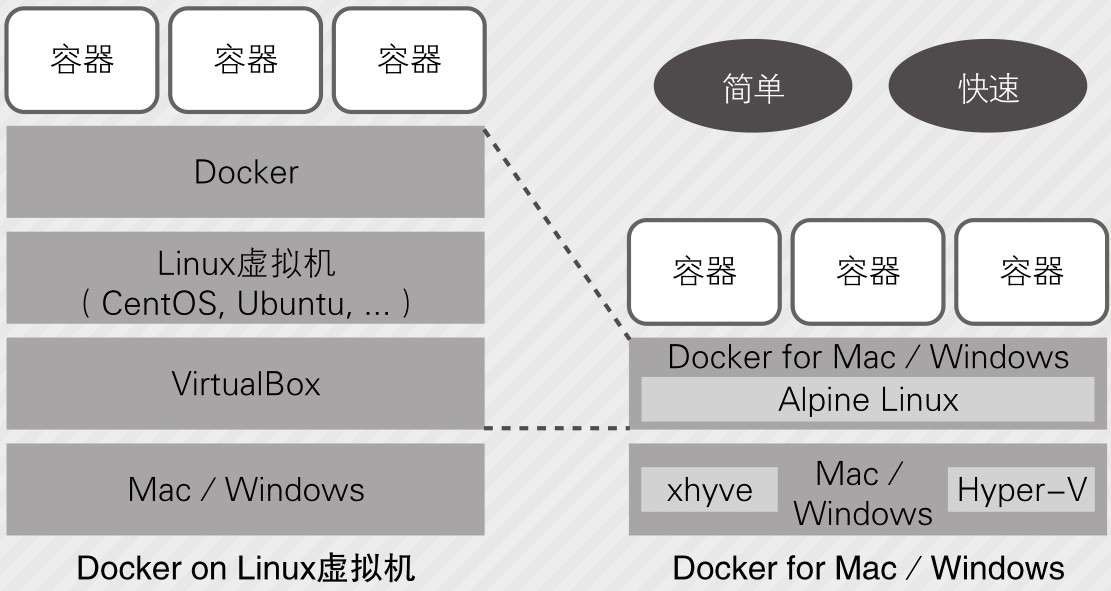
由于Docker需要在Linux下运行,所以需要在Mac或者Windows环境下运行一个Linux虚拟机。
在该工具内部也运行着一个Linux虚拟机,而Docker就运行在这个虚拟机中。
但是,这个Linux虚拟机在运行时实际使用的是操作系统原生支持的虚拟化技术,比如在Mac下会使用xhyve,在Windows下会使用Hyper-V,用户不需要再安装类似于VirtualBox这样的第三方虚拟化工具。
此外,基于“只需支持Docker运行即可”的思想,这个Linux虚拟机使用了Alpine Linux这一轻量级Linux发行版,使Docker运行起来更加便捷。DevOps领军人物约翰·威利斯(John Willis)在题为Docker and the Three Ways of DevOps的文章中介绍了DevOps的3种方式:
- 系统思考 System Thinking:Business|Dev -> Customer|Ops
- 增强反馈回路 Amplify Feedback Loops
- 培养不断实验和学习的文化 Culture Of Continual Experimentaion And Learning
使用Jenkins管理工作
以流水线的方式进行构建。
构建流水线工具,就是一个专门把构建及其相关处理关联起来执行的工具,如Jenkins。
任务管理工具是以在远程服务器上执行指定的处理为前提进行设计的,其设计思想在于,并非只在任务管理服务器上执行处理,而是在执行处理的节点上安装代理程序,然后通过代理来远程发布指令。将多个任务关联起来形成流水线的方法有两种:
一种是直接关联两个项目。通过定义项目的后续项目,将两个项目直接关联起来按顺序执行;
一种是以流水线的方式关联多个项目。定义一个用于统筹管理的项目,在这个项目中定义各个项目之间的关联性,然后以流水线的方式执行。使用持续集成和持续交付优化发布
只有提高了这一系列工作的效率,才能缩短整个开发周期。
不管是应用程序开发还是别的,尽早发现问题的“契机”,都是代码的修改。持续集成是一种开发方法,通过连续、自动地执行构建、测试和代码格式检查等功能实现相关的工作,在对软件或服务是否能正常工作进行细粒度的检查的同时不断推进开发。
持续集成的意思是连续执行一系列的操作。
持续集成的自动化到测试为止,而持续交付则将自动化扩展到了向生产环境发布前的最后一步。持续集成的目的:
- 在于降低工作成本和尽早发现问题。
- 尽早发现问题,持续交付的目的是实现快速发布,
- “执行测试”,那么持续交付的目标就是“结束所有测试”。
持续集成的优点:
- 尽早发现问题,保证系统质量
- 削减工作成本
- 使状态可视化
适合使用持续集成实现自动化的工作大致可分为以下几类:
- 应用程序的静态测试(静态检查)
静态测试指的是不用实际运行应用程序就可以执行的测试。
持续集成中常见的静态测试包括确认编程语言是否有编码错误的语法检查以及检查是否符合团队编码规范的静态解析等。 - 应用程序的构建
- 应用程序的动态测试
就软件开发阶段来说,这里指的是单元测试和集成测试。
持续集成工具必须具备的功能有下面这些:
- 可以定义触发操作的契机
- 可以进行各种操作
- 可以确认操作状态,保存所有操作记录
持续部署的目的是在生产环境中进行发布。
将服务发布到生产环境中,然后把价值交付给最终用户才是服务开发的最终目标。应用程序的开发工具:
编程语言 静态测试工具 构建工具 动态测试工具 Java SonarQube, FindBugs Ant, Mave, Gradle JUnit Ruby Rubocop Rake RSpec JavaScript ESLint, Closure Linter Grunt, Gulp PhantomJS + Jasmine, mocha + chai Golang Go Meta Linter 测试的种类:
测试内容 测试目的 单元测试、集成测试 确认应用程序中实现的各个功能是否能正常工作 安全测试 确认应用程序是否有预想中的安全漏洞 性能测试 确认应用程序是否能满足性能要求 压力测试 确认应用程序在一定的压力下是否还能正常工作 稳定性测试 确认应用程序或周围环境出现故障时,是否能按照预期的设计进行工作 验收测试 确认应用程序是否是按照客户的要求实现的 各种各样的持续实践:
持续实践 计划 实现 单元测试 构建 集成测试 交付 发布 运维 持续开发 Continuous Development + + 持续测试 Continuous Testing + + + 持续集成 Continuous Integration + + + + + 持续交付 Continuous Delivery + + + + + + 持续部署 Continuous Deployment + + + + + + + 持续所有 Continuous Everything + + + + + + + +
架构变革
改变应用程序架构
现代Web应用程序具体指以下内容:
- 使用标准化流程自动配置
- 应用程序具有可移植性,可以部署到云计算平台
- 可以不依赖开发环境和生产环境进行持续部署
- 不需要大的修改就能实现纵向扩展和横向扩展
现代Web应用程序需要遵循以下12个方法论来实现:
- 基准代码
应用程序应该基于在一个版本库中管理的一份代码,不管是测试环境还是生产环境,都可以使用这一份代码进行发布。 - 依赖
应在manifest文件(定义依赖关系的文件)中对应用程序和各种类库之间的依赖关系进行严格定义,确保应用程序不依赖于某一系统或类库。 - 配置
不要在代码中配置资源信息和环境信息(后端服务的连接信息、认证信息和主机名等),要把应用的配置存储于环境变量中。 - 后端服务
后端服务泛指可以跨网络访问的所有服务,包括数据存储、消息队列和缓存等。对于这些服务,我们不需要区分它们是本地服务还是云计算提供商提供的第三方服务,可以在不修改应用程序的情况下进行切换。 - 构建、发布、运行
代码发布之前的过程需要分为构建、发布和运行3个阶段:在构建阶段逐步解决依赖关系并在本地实施构建;在发布阶段将构建的结果与实际环境的配置相结合;在运行阶段在选定的资源上启动进程。 - 进程
进程需要设计为无状态,任何需要持久化的数据都要存储在后端服务内。进程也必须是无共享(shared nothing)的,各个进程之间相互独立,彼此自律地运行,不能存在任何共享的数据。会话可以放到数据存储中,要尽量避免设计成依赖于黏性会话(sticky session)的形式。 - 端口绑定
应用程序需要设计为自包含(self-contained)的结构,无须使用Apache或Tomcat等容器,应用程序直接通过端口绑定来对外提供HTTP服务。 - 并发
使用UNIX守护进程模型,把不同类型的工作负载(workload)分配给不同的进程,由此开发人员可以在设计时让应用程序支持多种工作负载。 - 易处理
应将启动时间缩到最短,也就是能够瞬间启动和停止服务,还要使进程在接收到SIGTERM信号之后实现优雅停止(grace shutdown)。 - 开发环境与线上环境等价
为了便于实现持续部署,需要尽量保证开发、预发布和生产环境一致。 - 日志
不要将日志写到文件里进行管理,而应将日志作为流(stream)输出,在设计时要保证日志流和输出目标或者存储等无关。 - 管理进程
数据库迁移、记录更新和运行调查用的命令等管理任务需要作为一次性进程运行,管理用的代码要和普通的应用程序代码放在同一个版本库中管理,并同时进行部署。
微服务架构:
微服务架构是一种将单个应用程序作为一套小型服务来开发的方法。每个小的服务都在自己的进程中运行,不同的进程之间使用轻量的HTTP资源API等方式进行通信。这些小的服务都是以业务功能为单位构建的,都可以采用自动化部署机制进行独立部署。由于各个进程相互独立,所以每个服务都可以采用不同的编程语言来编写,也可以使用不同的存储技术,不过这些服务要尽量保持最低限度的集中式管理。
微服务的9个特征,包括:服务组件化、以业务功能为中心组织团队、做产品的态度、服务端点、分布式治理、分布式数据管理、基础设施自动化、故障和演进设计。
针对脆弱系统的传统解决方案是提高系统的稳健性。其中一个方法就是冗余。通过将网络、服务器、数据库和存储冗余化,无论哪个组件发生故障,系统都不会整体瘫痪。
改变基础设施架构
使用不可变基础设施进行高效管理
不可变基础设施(immutable infrastructure)的思想,就是在基础设施构建完成后就不再进行任何变更。
想对基础设施进行变更时,全部重新构建。也就是说,在需要对环境进行操作时,需要先销毁现有的基础设施,然后再创建新的基础设施。不可变基础设施有如下几个优点:
- 可以防止意外发生
- 基础设施投入运行后,无须再对其配置和状态进行管理
- 可以强制实现基础设施即代码
- 可以统一故障处理和配置变更工作的步骤
不可变基础设施的缺点,就是不能让所有的基础设施都成为不可变的。
以Web服务器为代表的不包含任何状态的服务器称为无状态服务器。
DB服务器这种具备状态的服务器称为有状态服务器。
一般情况下,不可变基础设施只适用于无状态服务器。使用蓝绿部署切换服务
蓝绿部署(Blue-Green Deployment)的概念:- 生产环境由蓝色环境和绿色环境组成,用户只使用其中一个。从用户角度来说,不需要在意连接的是哪一个环境。
- 在用户没有使用的环境中实施发布工作,最后通过将前置(比如负载均衡器等)的连接切换到蓝色环境或绿色环境,从而瞬间完成环境的切换。
蓝绿部署会带来以下好处:
- 大部分发布工作可以在不影响用户使用的前提下完成
- 切换工作可以瞬间完成
- 发生故障时可以轻松回滚到以前的版本
确保用户能正常访问服务是最重要的目标
蓝绿部署也存在一些问题:
- 需要保持双重的基础设施
- 不适用于有状态服务器
如何实现蓝绿部署:
- 通过DNS进行切换
- 通过负载均衡器进行切换
- 通过Cookie进行切换
A/B测试,即检测用户行为的趋势,调查哪一种方案的满意度更高。具体来说,就是准备多种不同模式的服务,然后基于某种规则控制分发,观察用户的行为。
本地部署和公有云
本地部署(on-premise)是指公司自己购买或租赁服务器和网络设备,将其放置在自己的数据中心,然后由自己负责维护。这也是基础设施的传统使用场景。
在本地部署环境中使用OpenStack等云计算平台也可以像公有云一样基于虚拟机实现不可变基础设施,我们将这一架构称为私有云。公有云是指在互联网的云计算服务中对运行服务所需要的基础设施进行管理,构建系统所需要的服务器和网络设备也全都在互联网上。
公有云的优点是可以瞬间获得资源。SaaS
SaaS(Software as a Service,软件即服务)是指以服务的形式使用互联网提供的功能,并且可以按需使用、按量付费。
SaaS服务被广泛应用的本质在于优先追求商业价值,彻底削减非核心部分的成本。换句话说,就是将人力和系统资源分配到可以提高商业价值的地方,剩下的都以自动化的方式完成,以此降低资源的分配额度。
SaaS的思想是将运维等原本需要自己花费人力等资源去实施的工作外包出去。使用SaaS服务可以带来的好处:
- 使用门槛低,无须进行详细的配置和优化
- 能够及时为新的中间件或架构提供支持
- 不需要对SaaS服务进行运维工作
SaaS服务也有一些缺点:
- 无法对出现故障的SaaS服务进行控制
- 很难提供个性化的定制
- 不能自己决定价格和服务期限
常见的Saas服务列表:
功能 服务名 监控 Mackerel, New Relic, Datadog 可用性监控 Pingdom 持续集成 CircleCI, Travis CI 单点登录 OneLogin 事件管理 PagerDuty 仪表盘 Chartio 电话通知 twilio 日志分析 sumologic 日志收集和分析
改变团队
DevOps和敏捷开发
开发成功与否并不在于是否按计划准时发布了服务,而在于服务是否产生了商业价值。
DevOps的目的是提高商业价值。以迅速应对变化为目标的敏捷开发(agile development):“快速”“灵活”。
敏捷开发中有两个关键词,分别是“迭代”和“用户故事”。
迭代是在敏捷开发中以1~4周为单位进行短期的服务开发方式。
用户故事是指以文章的形式记录想要实现的功能。敏捷开发的基本形式就是以商业需求为核心,在较短期间内确定开发方针,并持续进行改善,从而逐步推进开发。
支持敏捷开发的开发方法:Scrum(争球)。
Scrum团队中包括3个角色:
- 产品负责人
产品负责人负责使Scrum团队开发的产品价值最大化。 - 开发团队
开发团队负责开发产品需要的各种功能。
开发团队的特征是自我管理,团队对自己开发的功能负责,自己制订具体的工作计划并进行管理。 - Scrum Master
Scrum Master负责对Scrum团队进行优化,检查Scrum团队是否符合Scrum开发的框架,在必要的情况下进行改善和教育工作。此外,Scrum Master还会对产品负责人提供支援、排除阻碍开发团队进行开发的因素。可以说Scrum Master是Scrum团队的管家。
Scrum开发流程:
- 发布计划
Scrum开发始于发布计划。在发布计划中,产品负责人处于中心位置,他会根据产品待办事项列表确定各功能的优先级,并确定需要多长时间来实现。 - 冲刺计划
冲刺计划是将产品待办事项列表中的功能开发映射到实际冲刺中的一个阶段。一次冲刺通常需要2~4周。 - 冲刺。
将实际开发交付成果物。相当于敏捷开发中的迭代。 - 每日站立会议
每日站立会议是指每天都会召开的简短会议,团队成员要在会议上简要汇报以下内容:- 昨天做了什么
- 今天要做什么
- 是否出现了什么阻碍开发正常进行的因素
- 冲刺评审
冲刺评审是对交付成果物进行评审的会议。冲刺评审中最重要的是直接展示可运行的服务。 - 冲刺回顾
Don’t just Do Agile, Be Agile(不要只照着敏捷的要求去做,而是要成为敏捷)
不满足于使用世界上已存在的各种方法和技术,而应把重点放在希望达到的效果上;
对希望达到的效果进行思考,不断根据变化来调整自身,才算得上是真正的敏捷开发。敏捷软件开发宣言: 个体和互动 高于 流程和工具 工作的软件 高于 详尽的文档 客户合作 高于 合同谈判 响应变化 高于 遵循计划- 产品负责人
ticket驱动开发
ticket驱动开发是在软件开发中使用JIRA、Redmine和Trac等缺陷跟踪系统(Bug Tracking System, BTS)或问题跟踪系统(Issue Tracking System, ITS),以ticket为单位对问题、缺陷以及敏捷开发中的用户故事等进行管理的方法。ticket驱动开发有一个规则,就是所有的代码提交都必须包含ticket。
网站可靠性工程(Site Reliability Engineering, SRE)
工程学 Engineering是“某个领域的技术集”。SRE团队的使命:
SRE团队负责可用性、延迟、性能、效率、变更管理、监控、紧急响应以及服务的容量规划。
an SRE team is responsible for availability, latency, performance, effciency, change management, monitoring, emergency response, and capacity planning.SRE团队的目的是提高网站可靠性,提升商业价值。
通过在平日里不断进行系统优化,使系统相关的所有人员都能够流畅地进行沟通。
提高网站可靠性的方法和观点:
- 系统优化
可用性,延迟、性能 - 监控
服务,容量。
服务监控是对当前系统状态的监控,那么容量监控则可以认为是对系统未来趋势的监控。 - 质量内建
实现自动化和省时省力,变更管理 - 故障处理
故障处理中最重要的是以较少的人在短时间内解决故障。应对故障的困难之处在于不知道故障什么时候发生。
故障处理的基本原则就是积极地让可以无条件执行恢复(回滚)操作的内容自动化。
- 系统优化
ChatOps
ChatOps是针对运维相关的各种任务,通过网络聊天工具来提高工作效率的一种方法。
Slack和Hubot是实现ChatOps的代表性组合。聊天工具由两部分构成:一部分是实现沟通的聊天系统;另一部分是从聊天系统中读取信息并执行相应操作的机器人系统。ChatOps具有以下优点:
- 统一沟通工具
- 操作更快捷
- 操作过程以及结果对所有人可见
- 事件以及与事件相关的沟通过程一目了然
进入运维阶段之后的工作和事件大致可举出以下几点:
- 任务操作
应用程序构建,测试,应用程序部署。 - 显示当前系统资源使用状况
- 接收报警通知
ChatOps由两个阶段组成:
- 聊天工具接收通知,团队成员基于通知进行沟通(系统→聊天工具→人)
- 通过聊天工具下达操作指令,实施具体操作(人→聊天工具→系统)
聊天工具介于口头沟通和邮件沟通之间,比口头沟通更加可靠,比邮件沟通更加快捷。
聊天工具比邮件好在哪里:
- 可以降低编写和传递信息的难度
- 可以将系统信息穿插在对话中
聊天工具比口头交流好在哪里:
- 沟通可以不受时间和空间的限制
- 保存沟通记录
- 方便和Web服务进行集成
DevOps团队的作用
故障处理
从运维人员的角度来说,服务的稳定运行是第一要务。
开发人员和运维人员的互相理解最终将有助于服务质量的提高。DevOps以精简的团队高效地进行运维,所以在发生故障时报警通知会发送给团队全体成员,由此将建立起一种大家可以一起参与到故障分析中的体制。
性能优化
开发人员以实现功能需求为第一要务。建立开发和运维之间的合作体制
DevOps需要的是开发部门和运维部门之间互相理解和互相合作,从而朝着共同的目标前进。
基础设施即代码
集成GitHub和Jenkins:
- 连接GitHub和Jenkins
- 在向GitHub远程仓库执行推送操作时自动开始Jenkins项目的构建。
这种自动触发的执行方式可以通过GitHub的Webhook和Jenkins的GitHub插件来实现。
如何实现更实用的架构?
最近出现的新服务并不追求在同一个服务中实现全部功能,而是在设计之初就考虑如何与其他服务进行集成和组合。另外,从用户的角度来看,通过组合使用不同的服务来提高自动化程度和效率也成为了主流思想。
不可变基础设施会从根本上改变基础设施的使用方式,DevOps不能单纯依靠工具或技术来实现。
DevOps工具和服务:
| 作用 | 产品 | 替代品 |
|---|---|---|
| 源代码管理 | GitHub | BitBucket, GitLab, GitBucket |
| 持续集成、工作流管理 | Jenkins | CircleCI, Travis CI, Consourse CI |
| 基础设施配置管理、部署 | Ansible | Chef, Puppet, Itamae |
| 聊天(沟通交流) | Slack | HipChat, Email |
Kibana菜单按钮的含义:
| 链接 | 说明 |
|---|---|
| Discover | 检索、查看数据 |
| Visualize | 创建并保存各种形式的图表,比如柱状图、饼图和直方图等 |
| Settings | 可以将 Visualize中保存的各种图表组合起来,以仪表盘的方式进行管理 |
| 时间窗口 | 设置图表中显示哪个时间段的数据。Kibana的一个页面中的所有图表都使用相同的时间范围。时间范围可以采用“昨天”“从x月x日到x月x日”“最近3小时”等形式 |
| 检索输入框 | 用于对图表中显示的数据进行筛选。比如,“只显示来自PC的访问”“只显示IP地址为xx的访问”“只显示HTTP状态码为200的数据”等 |
不可变基础设施中使用的服务或功能:
| 服务名 | 功能名 | 说明 |
|---|---|---|
| AWS | Amazon EC2 | Elastic Compute Cloud。AWS虚拟机 |
| AWS | ELB | Elastic Load Balancing。AWS负载均衡 |
| AWS | AWS CloudFormation | 可以基于模板通过一条命令创建各种AWS组件(比如EC2或者ELB等) |
| AWS | AWS CLI | 用于在命令行上执行AWS各种操作的命令集 |
| Ansible | Dynamic Inventory | 动态取得Ansible的Inventory,而不是固定地从文件中获取 |
跨越组织
在组织中实施DevOps
自上而下的方式 => 管理层,经理、领导,其他团队,团队成员 <= 自下而上的方式,在成员中普及
在新的组织中实施DevOps
在新的组织或新的服务开发中可以采用自上而下的方式实施DevOps。在既有组织中实施DevOps
在这种情况下,就需要由开发现场的人员来决定具体的实现方式,也就是通过自下而上的方式进行变革。
自上而下的方式有时也用于改善开发方式或服务体制,而不对组织本身进行大幅变革。在组织中采用自下而上的方式实施DevOps时需要特别注意的地方以及具体的应对策略:
- 确定目标
- 收集信息
可视化是指将每个人大脑中的内容文档化,或者将收集到的各种定量的数值信息(比如每次部署时各阶段所耗费的工作时间等)以图表的形式显示出来。 - 分析现状
在分析阶段,我们需要将这些信息分为两类:一类是对当前的工作步骤、任务和流程能起到根本作用的信息,一类是不能起到根本作用的信息。
按顺序将这些信息分为“必不可少的”和“不需要的”两类。 - 消除本质上不必要的工作和规则
- 寻找改变方法的切入点
- 实施
在输入和输出不变的前提下改变实现方法。 - 启蒙
- 检验效果并反馈给所有人
DevOps中的很多工具和方法的目的都是加快商业速度、提高开发效率。 - 全员参与,避免单打独斗
在不偏离总体目标的前提下进入下一个实施阶段
实施DevOps的反模式
采用某种工具或者某种架构只是实现DevOps的一种手段而已。
实施DevOps的方法是为了提高商业速度,构建精简的运维体制,创造出更好的服务。DevOps应始终保持开放,DevOps团队切记要让自己保持一种能和其他团队灵活交换意见的状态。
DevOps的本质就在于互相理解和学习,消除不必要的沟通,从而提高效率。在组织形式方面实施DevOps的最佳实践
DevOps的组织形式被划分为了下面3种类型:- 类型1:开发和运维之间的密切合作(Close-Knit Collaboration Between Dev & Ops)
Close-Knit的意思是“紧密地绑在一起”。 - 类型2:专门的DevOps团队(Dedicated DevOps Team)
Dedicated是“专属”的意思。 - 类型3:跨职能团队(Cross-functional teams)
Cross-functional是指“跨职能”,跨职能团队是指在从产品企划到发布之间的所有工程中召集各工程的专家代表组成的团队。
在不改变现有组织的情况下实施DevOps的方法:
通过组建临时团队或者采取技术性的解决方案也可以实现DevOps。- 类型1:开发和运维之间的密切合作(Close-Knit Collaboration Between Dev & Ops)
团队整体的DevOps
实现DevOps的第一步就是培育能够让团队成员相互协作的土壤,改善团队和组织的合作氛围,提高信息的公开性和透明性,使大家朝着同一个目标前进。
点评:作为入门的读物,还是可以的。但是总觉得有些空泛,不够具体深入。
DevOps实战笔记
极客时间 专栏
[中] 石雪峰(京东商城工具效率专家)
DevOps 状态报告,核心是看趋势、看模型、看实践。
《持续交付》围绕着软件交付的原则,给出了一系列的思想、方法和实践,核心在于:
以一种可持续的方式,安全快速地把你的变更(特性、配置、缺陷、试验),交付到生产环境上,让用户使用。
软件交付的 8 大原则:
- 为软件交付创建一个可重复且可靠的过程
- 将几乎所有事情自动化
- 将一切纳入版本控制
- 频繁地做痛苦的事情
- 内建质量
- DONE 意味着已发布
- 交付过程是每个成员的责任
- 持续改进
DevOps 产品的特点:技术背景要求高,面向的用户是开发人员,专业工具繁多。
DevOps 产品经理的修养:
- 自我颠覆
管理预期。如果产品使用场景有限,又没有很好的增长性,及时叫停反而是一种好的选择。 - 化繁为简
始终记得,不要让你的产品只有专家才会使用。将复杂的问题简单化,是产品经理不论何时都要思考的问题。 - 退后一步
不要把关注点只聚焦在问题表面,而是要尽量站在旁边,以第三方的视角来全面审视问题。
能够在用户思维和实现思维之间自由切换,是产品经理走向成熟的标志。
构建块 building block,是指一整块的代码片段,而不是一条条独立的指令。
DevOps文化:
协作、分享共担、无指责文化、在错误中学习。
通过对外开放透明,建立信任,促进协作;
打造心理安全的氛围,鼓励创新;
开源为先的共享精神。
对错误的态度和重视程度,决定了成长的高度。
假如说我要去一家公司面试,面试官问我有没有问题,那我非常关心的一定是他们公司对错误的态度,以及具体的实际行动。
美国硅谷的IT精英公司: FAANG = Facebook, Apple, Amazon, Netflix, Google
OKR = Objectives and Key Results 目标与关键成果法
是在硅谷互联网公司很流行的绩效制定方法。
O 代表目标,是我们要做什么。
KR 代表关键结果,用于验证我们是否已经达到了目标。
经典语录
- 每一家公司都将成为软件公司。
- 软件交付的效率和质量成了当今企业的核心价值和核心竞争力。
- 机制就是人们愿意做,而且做了有好处的事情。
- 新思想和新技术的发展,总是同标准化的模型和框架相伴相生的。
- 任何技术的成熟,都是以模型和框架的稳定为标志的。
- 啥都懂点儿,但是啥都不精通,本身就是IT从业者在职业发展道路上的大忌。
- 没有天然完美的解决方案,只有持续优化的解决方案。
- 持续改进和对人的尊重,才是一切改进方法的终极坐标。
- 不仅要低头看路,还要抬头看天。(仰望星空与脚踏实地)
- 任何技术的走向成熟,都是以模型和框架的稳定为标志的。
- 建立自己的知识体系,持续进行输出式学习。
- 完成比完美更重要,很多事情可以先干再说。
- 让计划帮你守住底线,让行动为成功添砖加瓦。
- 在企业中,要么提升自己的执行力,要么提升自己的创新力,要么让自己能够快速地整合资源,只有这样,你才能具备成功的资本。
- 每一行代码都是你的名片,每一个产品都是你的代言人。
- 但凡能打硬仗的同事,在后来都是非常靠谱且独当一面的,这与年龄无关,哪怕是应届生,也同样如此。
- Use what you build to build what you use.(使用你开发的工具来开发你的工具)
- 国家智库某领导:工业革命消灭了绝大多数的手工业群体,却催生了程序员这个现存最大的手工业群体。(手工作坊式的软件开发)
- 质量管理大师戴明博士:Don’t just do the same things better – find better things to do.
- 管理学大师爱德华·戴明博士:If you can’t measure it, you can’t manage it.
- 亚马逊CEO贝佐斯:要把战略建立在不变的事物上。
- 美国著名女演员莉莉·汤姆林 Lily Tomlin:The road to success is always under construction.(通往成功的道路,永远在建设之中)
基础理论
在传统模式下,开发团队,度量效率的途径是,看开发完成了多少需求。
运维团队,考核指标是,系统的稳定性、可用性和安全性。
定义
DevOps 是通过平台(Platform)、流程(Process)和人(People)的有机整合,以 C(Collaboration 协作)A(Automation 自动化)L(Lean 精益)M(Measurement 度量)S(Sharing 共享)文化为指引,旨在建立一种可以快速交付价值并且具有持续改进能力的现代化 IT 组织。
价值
DevOps 的 4 个结果指标:
- 部署频率:指应用和服务向生产环境部署代码的频率。
- 变更前置时间:指代码从提交到成功运行在生产环境的时长。
- 服务恢复时间:指线上应用和服务出现故障到恢复运行的时长。
- 变更失败率:指应用和服务在生产环境部署失败或者部署后导致服务降级的比例。
软件交付的两个最重要的方面:交付效率和交付质量。
DevOps的核心价值:高效率和高质量。
提升效率最直接的手段:工具和自动化。
DevOps 的行为准则:让一切都自动化。
实施
需要将规则内建于工具之中,并通过工具来指导实践。
DevOps 的 3 个支柱 = 人 People + 流程 Process + 平台 Platform
人 + 流程 = 文化
《一代宗师》:真正的高手,比拼的不是武功,而是思想。
DevOps 的文化就是指导 DevOps 落地发展的思想。责任共担,质量导向。流程 + 平台 = 工具
平台的最大意义,就是承载企业内部的标准化流程。
平台上固化的每一种流程,都是可以用来解决实际问题的工具。
平台因素:用户量、认可度、老板加持等。
平台的显著特征:- 吸附效应:平台会不断地吸收中小型的工具,逐渐成为一个能力集合体。
- 规模效应:平台的成本不会随着使用方的扩展而线性增加,能够实现规模化。
- 积木效应:平台具备基础通用共享能力,能够快速搭建新的业务实现。
工具是自动化的载体,自动化可以说是 DevOps 的灵魂。
平台就是搭台子,工具来唱戏。
- 平台 + 人 = 培训赋能
衡量
《跨越鸿沟》,技术采纳生命周期定律:一项新技术从诞生到普及要经历的 5 个阶段,分别对应一类特殊人群,即创新者、早期使用者、早期大众、晚期大众和落后者。技术的发展不是线性的,需要经历一段蛰伏期,才能最终跨越鸿沟为大众所接受,成为业界主流。
“道法术器”
数字化转型的核心在于优化软件交付效率。
模型和框架是能力和实践的集合。
ITIL V4 指导原则:关注价值、关注现状、交互式流程和反馈、协作和可视化、自动化和持续优化、极简原则、关注实践。
DevOps 工程师主要职责
工具平台开发,流程实践落地,技术预研试点。
理念和实践的宣导,内部员工的培训,持续探索,发现流程的潜在优化点等。
能力模型分为两个方面:
- 通用能力(软实力):沟通能力(向上沟通、向下沟通、横向沟通),学习能力,同理心
- 专业能力(硬实力):技术能力(代码能力、自动化能力、IT基础能力、容器云能力、业务和流程能力)
当硬实力到达天花板之后,软实力的差异将决定一个人未来的高度。
培养团队以用户为中心的思想。用户,不是外部用户,而是在交付流程中存在交付关系的上下游部门。
真正的学习者都是在没有条件来创造条件的过程中学习的。先干再说。
勤练习,多总结。就像 DevOps 一样,持续改进和持续反馈,培养自己的自信心。
企业需要的不仅仅是一个工具,而是工具所关联的一整套解决方案,其中最重要的就是业务流程。
落地实践
价值流
VSM = Value Stream Mapping 价值流图
价值是带给企业生存发展的核心资源,比如生产力、盈利能力、市场份额、用户满意度等。
VSM 是一场团队协作的试炼。
关键要素:
- 前置时间 LT=Lead Time
- 增值活动时间和不增值活动时间 VAT/NVAT=Value Added Time/Non-Value Added Time
- 完成度和准确度 %C/A=% Complete/Accurate。
开展 VSM 的 2 种方式:召开一次企业内部价值流程梳理的工作坊或者会议,内部人员走访。
VSM 的 5 大价值:看见全貌、识别问题、促进沟通、驱动度量、价值展现。
通过流程和平台的结合,来驱动流程的自动化流转,这才是 DevOps 的正确姿势。
DevOps 追求的是价值流动效率最大化。
转型
两种轨迹:一种是自底向上,一种是自顶向下。
寻求管理层的认可和支持都是一个必选项。
通用路径:
- 第 1 步:寻找合适的试点项目。贴近核心业务,倾向敏捷业务,改进意愿优先。
- 第 2 步:寻找团队痛点
- 第 3 步:快速建立初期成功
- 第 4 步:快速展示和持续改进
康威定律:一个团队交付的系统结构和他们的组织结构是相同的。
持续的增量交付和不断的反馈建议,也是现在保证产品需求有效性的最佳手段。
想要推进 DevOps,敏捷开发实践和需求价值分析都是必不可少的要素。
尽量避免从大型团队开始入手,专注于中型团队。
业务敏捷
交付能力的提升,可以帮助业务以最小的成本进行试错,将新功能快速交付给用户。
产品需求管理的核心思想:开发更少的功能,聚焦用户价值,持续快速验证
需求分析方法:影响地图。
影响地图是通过简单的“Why-Who-How-What”分析方法,实现业务目标和产品功能之间的映射关系。
- Why 代表目标,它可以是一个核心的业务目标,也可以是一个实际的用户需求。
- Who 代表影响对象,通过影响谁来实现这个目标。
- How 代表影响,怎样影响用户以实现我们的目标。
- What 代表需要交付什么样的功能,可以带来期望的影响。
需求优先级安排:
卡诺模型(Kano Model),日本大师授野纪昭博士提出的一套需求分析方法。
核心要做到3点:优先规划期望型和必备型需求,识别无差别型和反向型需求,追求兴奋型需求。
卡诺模型将产品需求划分为五种类型:
- 兴奋型:指超乎用户想象的需求,是可遇不可求的功能。
- 期望型:用户的满意度会随着这类需求数量的增多而线性增长,做得越多,效果越好,但难以有质的突破。
- 必备型:产品必须要有的功能,如果没有的话,会带来非常大的影响。
- 无差别型:做了跟没做一样,典型的无用功。
- 反向型:无中生有类需求,实际上根本不具备使用条件,或者用户压根不这么想。
用户故事则是以用户的价值为核心,圈定一种角色,表明通过什么样的活动,最终达到什么样的价值。
检验用户故事拆分粒度是否合适,可以遵循 INVEST 原则:
- Independent 独立的:减少用户故事之间的依赖,可以让用户故事更加灵活地验证和交付,而避免大批量交付对于业务敏捷性而言至关重要。
- Negotiable 可协商的:用户故事不应该是滴水不漏、行政命令式的,而是要抛出一个场景描述,并在需求沟通阶段不断细化完成。
- Valuable 有价值的:用户故事是以用户价值为核心的,每个故事都是在对用户交付价值,要站在用户的视角思考问题,避免“我不要你觉得,我要我觉得”。
- Estimatable 可评估的:用户故事应该可以粗略评估工作量,无论是故事点数还是时间,都可以。如果是一个预研性质的故事,则需要进一步深挖可行性,避免不知道为什么做而做。
- Small 小的:用户故事应该是最小的交付颗粒度,所以按照敏捷开发方式,无论迭代还是看板,都需要在一个交付周期内完成。
- Testable 可测试的:验收条件,如果没有办法证明需求已经完成,也就没有办法进行验收和交付。
需求价值的度量:
- 客观指标:客观数据能够表明的指标。如加入购物车率、完成订单率等。
- 主观指标:无法直接度量,只能通过侧面数据关联得出。如用户体验、用户满意度、用户推荐率等。
Business + DevOps = BizDevOps,核心理念:
- 对齐业务和开发目标、指标
- 把握安全、合规指标
- 及时对齐需求,减少无用开发
- 体现 DevOps 的价值
- 让开发团队开始接触业务,不单单是执行,调动积极性
Security + DevOps = DevSecOps
精益看板
敏捷常用的两种框架:Scrum 和看板。
看板,日语词汇,カンバン / Kanban,泛指日常生活中随处可见的广告牌。
精益看板的核心是关注价值流动,加速价值流动。在软件开发中,价值可能新功能、缺陷修复、体验优化。
核心实践是限制在制品数量。
利特尔法则:平均吞吐率 = 在制品数量 / 平均前置时间。
在制品数量是当前团队并行处理的工作事项的数量。
前置时间,衡量 DevOps 产出效果的核心指标,代表从需求交付开发开始到上线发布这段时间的长度。
实践方法步骤:
- 第一步:可视化流程;
- 第二步:定义清晰的规则;
- 第三步:限制在制品数量;
- 第四步:管理工作流程;
- 第五步:建立反馈和持续改进。
看板方法是一种相对温和的渐进式改进方法。
可视化的意义不仅在于让人看得见,还在于让人看得懂。
限制在制品数量有两个关键节点:一个是需求流入节点,一个是需求交付节点。
DevOps 的倡导理念是“You build it,you run it”。要想做到业务敏捷,就得想发就发,做完一个上一个。
在看板方法中,常见的有三种会议:
- 每日站会
关注两点:待交付的任务,紧急、缺陷、阻塞和长期没有更新的任务。 - 队列填充会议
目标有两点:一个是对任务的优先级进行排序,一个是展示需求开发的状态。 - 发布规划会议
以最终交付为目标,实现按节奏部署和按需发布。
配置管理
四个核心理念:版本变更标准化,将一切纳入版本控制,全流程可追溯,单一可信数据源。
变更:对软件做的任何改变。
一套标准化的规则和行为习惯,可以降低协作过程中的沟通成本,一次性把事情做对,这也是标准和规范的重要意义。
标准化是自动化的前提,自动化又是 DevOps 最核心的实践。
“什么什么即代码”,其背后的核心都是版本控制。
如果这个产物可以通过其他产物来重现,那么就可以作为制品管理,而无需纳入版本控制。
把握源头,建立主线。所谓源头,对于软件开发而言,最原始的就是需求,所有的变更都来源于需求。
对于任何一家企业来说,信息过载都是常态,而配置管理的最大价值正是将信息序列化,对信息进行有效的整理、归类、记录和关联。
分支策略
分支策略就是软件协作模式和发布模式的风向标。
主干开发,分支发布
在软件版本发布之前,会基于主干拉出一条以发布为目的的短分支。分支开发,主干发布
当开发接到一个任务后,会基于主干拉出一条特性开发分支,在特性分支上完成功能开发验证之后,通过 Merge request 或者 Pull request 的方式发起合并请求,在评审通过后合入主干,并在主干完成功能的回归测试。可以加快代码集成频率,特性相对独立清晰。
如开源社区流行的 GitHub 模式。
遵守原则:- 团队共享一条主干分支;
- 特性分支的存活周期要尽量短,最好不要超过 3 天;
- 每天向主干合并一次代码,如果特性分支存在超过 1 天,那么每天都要同步主干代码;
- 谨慎使用功能开关等技术手段,保持代码干净和历史清晰;
- 并行分支越少越好,如果可能的话,尽量采用主干发布。
主干开发,主干发布
团队只有一条分支,开发人员的代码改动都直接集成到这条主干分支上,软件的发布也基于这条主干分支进行。
持续集成
CI = Continuous Integration 持续集成
马丁·福勒 Martin Fowler:
CI 是一种软件开发实践,团队成员频繁地将他们的工作成果集成到一起(通常每人每天至少提交一次,这样每天就会有多次集成),并且在每次提交后,自动触发运行一次包含自动化验证集的构建任务,以便尽早地发现集成问题。
核心理念是:越是痛苦的事情,就要越频繁地做。
工具是实践的载体,实践是工具的根基。
三个阶段:
- 第一阶段:每次提交触发完整的流水线。快速集成。
前置条件:统一的分支策略,清晰的集成规则,标准化的资源池,足够快的反馈周期。 - 第二阶段:每次流水线触发自动化测试。质量内建。
关注点:匹配合适的测试活动,树立测试结果的公信度,提升测试活动的有效性。 - 第三阶段:出了问题可以在第一时间修复。文化建立。
人不是关键,建立机制才是关键。机制是一种约定,人们愿意遵守这样的行为,并且做了会得到好处。
极限编程 XP = ExtremeProgramming,是一种软件开发方法,作为敏捷开发的方法之一,目的在于通过缩短开发周期,提高发布频率来提升软件质量,改善用户需求响应速度。
自动化测试
测试三角形模型描述了从单元测试、集成测试到 UI 测试的渐进式测试过程。
自动化测试误报率 = 非开发变更引入的问题用例数量 / 测试失败的用例数量
测试误报率是体现自动化测试稳定性的一个核心指标。
内建质量
内建质量扭转了看待产品质量的根本视角,团队所做的一切不是为了验证产品存在问题,而是为了确保产品没有问题。
内建质量的两个核心原则:
- 问题发现得越早,修复成本就越低;
- 质量是每个人的责任,而不是质量团队的责任。
尽早发现问题,尽早解决。
Fail fast 快速失败。停止生产不是目的,及时发现问题和解决问题才是目的。
零缺陷,并不是说产品的 Bug 数量等于零,其实是一种质量观念,倡导全员质量管理,构建质量文化。每一个人在工作的时候,都要力争第一时间发现和解决缺陷。
质量是生产出来的,而不是测试出来的。
研发环节作为整个软件产品的源头,是内建质量的最佳选择。
核心目标不是为了通过质量门禁,而是为了质量提升。
实施步骤:
- 第一步:选择适合的检查类型。
- 第二步:定义指标并达成一致。
度量指标分两个层面,一个是指标项,一个是参考值。
指标项是针对检查类型所采纳的具体指标。
参考值推荐静态指标+动态指标。
静态指标是固定值。动态指标是以考查增量和趋势为主。 - 第三步:建立自动化执行和检查能力。
- 第四步:定义问题处理方式。
- 第五步:持续优化和改进。
技术债务
技术债务,是指团队在开发过程中,为了实现短期目标选择了一种权宜之计,而非更好的解决方案,所要付出的代价。这个代价就是团队后续维护这套代码的额外工作成本,并且只要是债务就会有利息,债务偿还得越晚,代价也就越高。
技术债务最直接的影响就是内部代码质量的高低。
三方面影响:
- 额外的研发成本
- 不稳定的产品质量
- 难以维护的产品
量化技术债务
在 SonarQube 中,技术债是基于 SQALE 方法计算出来的。
SQALE = Software Quality Assessment based on Lifecycle Expectations 基于生命周期期望的软件质量评估,是一种开源算法。
SQALE 评估代码质量的级别为 A、B、C、D、E。A 是最高等级,意味着代码质量水平最高。
技术债务比例 = 修复已有技术债务的时间 / 完全重写全部代码的时间
《Sonar Code Quality Testing Essentials》,代码的“七宗罪”:
| 类型 | 影响 |
|---|---|
| 不能均匀分布的复杂性 | 较高的圈复杂度需要更多的测试才能覆盖到全路径,导致潜在的功能质量风险。 |
| 重复代码 | 重复代码是最严重的问题,会导致潜在缺陷。另外,重复也会带来维护成本的增加。 |
| 不合适的注释 | 代码的注释没有明确标准。缺少关键环节的注释或者是注释难以理解,都会导致代码的可读性变差。 |
| 违反代码规范 | 影像团队基于共同的规范进行写作,会增加潜在的风险。 |
| 缺乏单元测试 | 单元测试不足会影响团队对代码的信心,增加重构成本,通过测试覆盖率对其进行度量。 |
| 缺陷和潜在的缺陷 | 缺陷和潜在缺陷是最直接影响代码质量的要素,要尽可能地发现并修复。 |
| 设计和系统架构 | 设计和系统架构受限于当时的资源条件,可能无法满足后续产品的发展需求,所以需要持续演进。 |
解决方法:共识,可见,止损,改善。
解决原则:让技术债务呈良性下降趋势。优先解决高频修改的问题。在新项目中启动试点。技术债务无法被消灭,也不要等到太晚。
环境管理
环境管理的挑战:环境种类繁多,环境复杂性上升,环境一致性难以保证,环境交付速度慢,环境变更难以追溯。
基础设施即代码:用一种描述性的语言,通过文本管理环境配置,自动化完成环境配置的方式。
典型的自动化环境配置开源管理工具,CAPS = Chef、Ansible、Puppet、Saltstacks
通过将所有环境的配置过程代码化,每个环境都对应一份配置文件,可以实现公共配置的复用。
环境的配置过程,完全可以使用工具自动化批量完成。
GitOps = 版本控制系统 + 基础设施即代码
核心在于通过代码化的方式来描述应用的部署环境和部署过程。
有利于环境配置的共享和统一管理。
无论采用什么技术,代码化管理的方式都是未来的发展趋势。
部署管理
四个核心的结果指标:
部署频率,部署失败率,前置时长,平均故障修复时长。
部署 Deploy,是一组技术实践,表示通过技术手段,将本次开发测试完成的功能实体(比如代码、二进制包、配置文件、数据库等)应用到指定环境的过程,包括开发环境、预发布环境、生产环境等。
部署的结果是对服务器进行变更,但是这个变更结果不一定对外可见。
发布 Release,是将部署完成的功能正式生效,对用户可见和提供服务的过程。更偏向一种业务实践。
发布的时机往往同业务需求密切相关。很多时候,部署和发布并不是同步进行的。
DevOps 模式下的质量思想:要在保障一定的质量水平的前提下,尽量加快发布节奏,并通过低风险发布手段,以及线上测试和监控能力,尽早地发现问题,并以一种最简单的手段来快速恢复。
一定的质量水平。
质量不再是测试团队自身的事情,而是整个交付团队的事情。
低风险发布手段:
- 蓝绿部署
- 灰度发布/金丝雀发布。实现机制之一:渐进式的滚动升级
- 暗部署。在用户不知道的情况下进行线上验证
线上测试和监控:
监控就是一种全量的测试
常用手段:
- 采用灰度发布、用户众测等方式,逐步观察用户行为并收集用户数据,以验证新版本的可用性是否符合预期
埋点功能。 - 用户反馈
用户运营和舆情监控系统。 - 使用线上流量测试
流量镜像,GoReplay 工具
快速恢复:
- 阿里的开源工具 Arthas
- 向前修复和向后回滚
向前修复:快速修改代码并发布一个新版本上线。
向后回滚:将系统部署的应用版本回滚到前一个稳定版本。 - 服务降级和兜底策略
服务降级:在流量高峰的时候,将非主路径上的功能进行临时下线,保证业务的可用性。
兜底策略:常见的做法是缓存和兜底页面,以及前端比较流行的骨架屏等。
混沌工程
混沌工程是一门在分布式系统上进行实验的学科,目的是建立人们对于复杂系统在生产环境中抵御突发事件的信心。
混沌工程不是为了制造问题,而是为了揭示问题。
尽可能在这些故障和缺陷发生之前,通过一系列的实验,在真实环境中验证系统在故障发生时的表现。
故障演练:针对以往发生过的问题进行有针对性地模拟演练。
从业务层面来说,面对多变的环境因素,完善的服务降级预案和系统兜底机制也是必不可少的。适当地引入排队机制。
混沌工程的原则:
建立稳定状态的假设
参考指标:指标类型 指标示例 业务核心指标 用户数、活跃用户数、新增用户数、订单量、GMV、平均客单价、转化率、订单成功率、订单取消率、订单退货率、商品和商家数量 业务访问指标 UV、PV、点击率、首页到达率、商品到达率、评论到达率 用户体验指标 用户满意度、用户投诉数量、用户反馈数量、订单好评率、订单差评率 系统指标 QPS、TPS、CPU使用率、CPU负载、内存使用率、网络连接数、平均响应时长、404数量 真实世界的事件
投入产出比最高的就是选择重要指标(比如设备可用性、网络延迟,以及各类服务器问题),进行有针对性地实验。在生产中试验
要求实验范围可控,并且具备随时停止实验的能力。如果系统没有为弹性模式做好准备,就不要开启生产实验。持续的自动化实验
自动化是所有重复性活动的最佳解决方案。最小的影响范围
正向度量
对于 IT 交付,DevOps 希望做到的是持续、快速和高质量的价值交付。
好的指标一般具备四种特性:明确受众、直指问题、量化趋势、充满张力。
好的指标应该是可以衡量的,是可以通过客观数据来自证的;向上可以归并到业务结果,向下可以层层分解到具体细节。
DevOps 度量的五条原则:
全局指标优于局部指标,综合指标优于单一指标,结果指标优于过程指标,团队指标优于个人指标,灵活指标优于固化指标。
DevOps度量指标:
- 交付效率
- 需求前置时间:从需求提出到完成整个研发交付过程,并最终上线发布的时间。
需求侧,从需求提出、分析、设计、评审到就绪的时长
业务侧,研发排期、开发、测试、验收、发布的时长。 - 开发前置时间:从需求进入排期、研发真正动工的时间点开始,一直到最终上线发布的时长。
- 需求前置时间:从需求提出到完成整个研发交付过程,并最终上线发布的时间。
- 交付能力
- 发布频率:单位时间内的系统发布次数。原则上发布频率越高,代表交付能力越强。
- 发布前置时间:研发提交一行代码到最终上线发布的时间。
- 交付吞吐量:单位时间内交付的需求点数。
- 交付质量
- 线上缺陷密度:单位时间内需求缺陷比例。即平均每个需求所产生的缺陷数量;缺陷越多,说明需求交付质量越差。
- 线上缺陷分布:所有缺陷中的严重致命等级缺陷所占的比例。比例数值越高,说明缺陷等级越严重。。
- 故障修复时长:从有效缺陷提出到修复完成并上线发布的时间。
开启度量工作的步骤:
- 第 1 步:细化指标
- 第 2 步:收集度量数据
- 第 3 步:建立可视化平台
- 第 4 步:识别瓶颈并持续改进
细化的交付指标
指标维度:交付质量
| 指标名称 | 线上缺陷密度 | 缺陷分布 | 故障修复时长 |
|---|---|---|---|
| 指标描述 | 单位时间内需求缺陷比例(单位需求缺陷数量) | 严重致命等级缺陷占比 | 有效缺陷提出到修复的周期 |
| 指标级别 | 高 | 高 | 高 |
| 指标类型 | 结果指标 | 结果指标 | 结果指标 |
| 数据来源 | 需求管理平台、缺陷管理平台 | 缺陷管理平台 | 缺陷管理平台、质量管理平台 |
| 计算公式 | =∑线上P4级别以上缺陷数/2统计周期内上线发布需求个数 | =∑严重致命等级缺陷数量/2统计周期内所有级别缺陷数量 | =故障修复时间-故障识别时间 |
| 参考值 | <2‰ | <5% | < 60min |
| 使用场景 | 产品研发度量报告、产品研发沟通月会、度量平台质量视图 | 产品研发度量报告、产品研发沟通月会、度量平台质量视图 | 产品研发度量报告、产品研发沟通月会、度量平台质量视图 |
| 目标受众 | 全体产研成员 | 全体产研成员 | 全体产研成员 |
| 负责团队 | 质量管理组 | 质量管理组 | 质量管理组 |
度量的真正目的是团队效率的提升和业务的成功。
只有通过度量激起团队自发的改进意愿,提升团队改进的创造性和积极性,才是所谓的“正向度量”。
持续改进
始终能够找到新的突破,持续追求更好的状态。
构建持续改进的核心,就在于构建一个学习型组织。
质量管理大师戴明博士,戴明环 PDCA = Plan 计划, Do 实施, Check 检查, Action 行动
平台工具
平台建设
当企业决定引入 DevOps 工具时,有三种选择:直接使用开源工具;采购商业工具;自己研发工具。
企业 DevOps 平台建设的三个阶段:
阶段一:从无到有
引入开源工具和商业工具,快速补齐现有的能力短板。
能力短板:当前交付工具链体系中缺失的部分,尤其是高频操作,或者是涉及多人协作的部分,比如需求管理、持续集成等。选择主流工具:
需求管理工具 Jira;
知识管理工具 Confluence;
版本控制系统 GitLab;
持续集成工具 Jenkins;
代码质量工具 SonarQube;
构建工具 Maven/Gradle;
制品管理 Artifactory/Harbor;
配置管理工具 Ansible;
配置中心 Apollo;
测试工具 RF/Selenium/Appium/Jmeter/TestNG;
安全合规工具 BlackDuck/Fortify;
……阶段二:从小到大
使用半自建工具和定制商业工具,来解决自己的问题。
半自建工具:大多数情况下,仍是基于开源工具的二次开发,或者是对开源工具进行一次封装,在开源工具上面实现需要的业务逻辑和交互界面。
注意事项:设计时给扩展留出空间;实现时关注元数据治理。阶段三:从繁到简
使用整合工具来化繁为简,统一界面,简化操作,有效度量。
企业工具平台治理/平台化治理工作的建议:找到软件交付的主路径;区分平台和工具,让平台脱颖而出。
打造自服务的工具平台。
自服务:用户可以自行登录平台实现自己的操作,查看自己关心的数据,获取有效的信息。
指导平台建设的核心理念:“四化”:
- 标准化:一切皆有规则,一切皆有标准
- 自动化:干掉一切不必要的手工操作环节,能一键完成的,绝不操作两次
- 服务化:面向用户设计,而不是面向专家设计,让每个人都能在没有外界依赖的前提下,完成自己的工作
- 数据化:对数据进行收集、汇总、分析和展示,让客观数据呈现出来,让数据指导持续改进
产品设计
无论什么产品,其实都是为了解决一群特定的人在特定场景的特定问题。
产品设计体验的五个层次:
- 战略存在层
始终着眼于那些长久不变的事物之上,即“多、快、好、省”。
作为DevOps 产品战略定位的永远不变的东西:效率、质量、成本、安全。
产品的任何功能都是要为战略服务的。 - 能力圈层
产品化:将一个战略或者想法通过产品分析、设计、实验并最终落地的过程。
零和游戏:所有玩家资源总和保持固定,只是在游戏过程中,资源的分配方式发生了改变。
主航道和护城河理论:主航道,是产品的核心能力,直接反射了产品战略的具体落地方式。护城河是产品的不可替代性,或者是为了替代产品需要付出的高额代价。 - 资源结构层
核心竞争力即对资源的整合和调动能力。 - 角色框架层
不要让你的产品只有专业人士才会使用。
产品应该提供抽象能力屏蔽很多细节,而不是暴露很多细节。好的产品自身就是使用说明书。 - 感知层
建议:多跟前端工程师交流,多学习一些基本的设计原则,如一致、反馈、效率、可控。
持续交付平台
流水线是持续交付中最核心的实践,也是持续交付实践最直接的体现。
现代流水线设计的十大特性:
特性一:打造平台而非能力中心
流水线平台是唯一一个贯穿软件交付端到端完整流程的平台。
流水线的主要作用是驱动软件交付过程的效率提升和状态可视化。
正确的做法:将持续交付流水线平台和垂直业务平台分开,并定义彼此的边界。流水线平台只专注于流程编排、过程可视化,并提供底层可复用的基础能力。比如运行资源池、用户权限管控、任务编排调度流程等等。
流水线平台仅作为任务的调度者、执行者和记录者,不需要侵入垂直业务平台内部。垂直业务平台:单一专业领域的能力平台,比如自动化测试平台、代码质量平台、运维发布平台等等,是软件交付团队日常打交道最频繁的平台。
垂直业务平台专注于专业能力的建设、一些核心业务的逻辑处理、局部环节的精细化数据管理等。
垂直业务平台可以独立对外服务,也可以以插件的形式,将平台能力提供给流水线平台。特性二:可编排和可视化
流程可编排能力:用户可以自行定义软件交付过程的每一个步骤,以及各个步骤之间的先后执行顺序。
编排的前提是系统提供了可编排的对象,一般称为原子。
原子:一个能完成一项具体的独立任务的组件;组件具备一定的通用性,尽量与业务无关。特性三:流水线即代码 Pipeline As Code
比如Jenkins 2.0 中引入的 Jenkinsfile。特性四:流水线实例化
流水线需要支持参数化执行。
流水线的每一次执行,都是一个实例化的过程。
流水线需要支持并发执行能力。特性五:有限支持原则
流水线的设计目标,应该是满足大多数、常见场景下的快速使用,并提供一定程度的定制化可扩展能力,而不是满足所有需求。
用户的差异化诉求,可以在平台中提供一些通用类原子能力,比如执行自定义脚本的能力、调用 HTTP 接口的能力、用户自定义原子的能力等等。特性六:流程可控
事件触发。比如Gitlab Webhook。特性七:动静分离配置化
动静分离是一种配置化的实现方式。
将需要频繁调整或者用户自定义的内容,保存在一个静态的配置文件中。系统加载时通过读取接口获取配置数据,并动态生成用户可见的交互界面。
设计标准化的系统的最佳实践是定义一个通用的数据结构。特性八:快速接入
提供插件机制,实现平台能力的接入。
接入成本的高低,直接影响了平台能力的拓展;流水线平台支持的能力多少,就是平台的核心竞争力。
轻量化的平台接入方法:自动化生成平台关联的原子代码。外部平台打通的两种类型:
- 平台方提供本地执行的工具。类似 SonarQube 的 Scanner 方式,通过在本地调用该工具,实现相应的功能。
- 通过接口调用的方式。实现平台与平台间的交互,调用的实现过程有同步和异步两种模式。
流水线平台需要定义一套标准的接入方式。
以接口调用类型为例,接入平台需要提供一个任务调用接口、一个状态查询接口以及一个结果上报接口。- 任务调用接口:用于流水线触发任务。由接入平台定义和实现。
- 状态查询接口:用于流水线查询任务的执行状态,获取任务的执行进度。由接入平台定义和实现的,返回的内容包括任务状态、执行日志等。
- 数据上报接口:用于任务将执行结果上报给流水线平台进行保存。由流水线平台定义,并提供一套标准的数据接口给到接入方。
特性九:内建质量门禁
在流水线平台上,要完成质量规则制定、门禁数据收集和检查、门禁结果报告的完整闭环。策略模式的核心就在于面向接口而非面向过程开发,通过实现不同的接口类,来实现不同的检查策略。
特性十:数据聚合采集
上报数据的颗粒度,原则就是满足用户对最基本的结果数据的查看需求。
数据度量平台
要解决的核心问题是软件研发过程可视化。
度量平台建设的思路:
- 事前:指标共识
度量指标是数据度量平台的基础。
比如开发交付周期指标的描述是:从研发在需求管理平台上将一个任务拖拽到开始的开发阶段起,一直到这个任务变成已发布状态为止的时间周期。 - 事中:平台建设
数据获取:- 挑战一:大量数据源平台对接
插件化,实现数据采集器。 - 挑战二:海量数据存储分析
数据度量平台一般都会保存元数据和加工数据。
元数据:采集过来的、未加工过的数据。建议:非结构化数据存储的数据库,支持分布式存储系统 - HBase
加工数据:经过数据清洗和数据处理的数据。建议:关系型数据库 - MySQL - 挑战三:度量视图的定制化显示
可以利用现有的前端组件来实现可视化界面展示。
- 挑战一:大量数据源平台对接
- 事后:规则落地
尽量实现自动化操作,而不是依赖于人的自觉性。
度量的目的是持续改进。
平台产品研发
项目启动
系统方案选型;建立协作机制。
建立固定的沟通机制就非常重要。重点关注的几件事情:
- 明确项目目标,树立团队的信心
- 沟通开发模式和技术架构选型,以快速开发和简单上手为导向
- 建立沟通渠道,保持高频联系
- 识别项目的技术风险,提前开启专项预研
开发策略
环境容器化。开发协作流程
内部“3-2-1”原则:- 3:创建任务三要素
有详细的问题说明和描述
有清晰的验收标准
有具体的经办人和迭代排期 - 2:处理任务两要素
在开发中,代码变更要关联 Jira 任务号
在开发完成后,要添加 Jira 注释,说明改动内容和影响范围 - 1:解决任务一要素
问题报告人负责任务验收关闭
- 3:创建任务三要素
产品运营策略
打广告,如流量高的地方,技术分享上宣传。团队文化建设
- 让专业的人做专业的事情
- 抓大放小,适当地忽略细节
开源工具
对于持续交付工具链体系,工具的连通性是核心要素。
需求管理 - Jira
代码管理 - GitLab
代码质量 - SonarQube
环境管理 - Kubernetes
JNLP = Java Network Launch Protocol,是一种通用的远程连接 Java 应用的协议方式。
流水线工具对比:
| 工具 | 易用性 | 流水线设计 | 插件生态 | 扩展性 | 适用场景 |
|---|---|---|---|---|---|
| Jenkins | 低 | Groovy代码(支持描述式语法和可视化编辑) | 高 | 低 | 各种规模团队和各种产品形态,需要有专人维护 |
| Jenkins X | 低 | Yaml | 高 | 高 | 云原生开发场景,遵循开发流程,小规模试点团队,不建议生产使用 |
| GitLab CI | 中 | Yaml | 低 | 中 | 中大型团队,不建议小型团队使用(系统维护成本高) |
| GitHub Actions | 中 | Yaml(支持可视化编辑) | 高 | 中 | 开源产品或初创产品,不适合企业级应用(商业化问题) |
| Drone | 高 | Yaml | 中 | 高 | 中小型团队,云原生开发场景 |
Cloud native computing uses an open source software stack to deploy applications as microservices, packaging each part into its own container, and dynamically orchestrating those containers to optimize resource utilization.
云原生使用一种开源软件技术栈来部署微服务应用,将每个组件打包到它自己的容器中,并且通过动态编排来优化资源的利用率。
云原生应用的12要素:
- 基准代码∶一份基准代码、多份部署。
- 依赖:显式声明依赖关系。
- 配置:在环境中存储配置。
- 后端服务:把后端服务当作附加资源。
- 构建、发布、运行∶严格分离构建、发布和运行。
- 进程:以一个或多个无状态进程运行应用。
- 端口绑定∶通过端口绑定提供服务。
- 并发:通过进程模型进行扩展。
- 易处理∶快速启动和优雅终止,最大化健壮性。
- 开发环境与线上环境等价∶尽可能保持开发、预发布、线上环境相同。
- 日志:把日志当作事件流。
- 管理进程:把后台管理当作一次性进程运行。
云时代,一切皆服务。
Jenkins X + Tecton:
自动化生成依赖的配置文件
Dockerfile:用于生成 Docker 镜像
Jenkinsfile:应用关联的流水线配置
Helm Chart:把应用打包并部署运行在 Kubernetes 上的资源文件
Skaffold:用于在 Kubernetes 中生成 Docker image 的工具自动化流水线过程
用到的技术:- 流水线即代码。只有代码化的流水线配置才有可能自动化。
- 流水线的抽象和复用。以 Jenkinsfile 为例,大多数操作应该提取到公共库 shared library,以提升抽象水平和能力复用。
- 流水线的条件判断。对于同一条流水线来说,根据不同的条件,可以实现不同的执行路径。
自动化多环境部署
将云原生应用部署在 Kubernetes 上时,所有依赖都是环境中的资源。使用云原生流水线
Jenkins X 提供了上层抽象,通过 YAML 文件的形式描述整个交付过程。
Tekton 提供了最底层的能力。
在后台,Jenkins X 将这个文件转换成 Tekton 需要使用的 CRD 资源并触发 Kubernetes 执行。
用户看起来还是在使用 Jenkins,实际上,流水线的执行引擎已经从原来的 JVM 变成了现在 Kubernetes。流水线的执行和调度由 Kubernetes 来完成,整个过程中每一步的环境都是动态初始化生成的容器,所有的数据都是通过外部存储来保存的。CRD = Custom Resource Definition 自定义资源定义
云原生关键技术:容器,容器编排,微服务、服务网络,不可变基础,声明式 API,DevOps。
不可变基础设施是现代运维的基石,
容器编排Kubernetes是整个云原生的基石,
容器是Kubernetes的底层引擎,Docker是应用最广的容器工具,
微服务是Docker的好搭档,
服务网格是微服务的辅助,建立在Kubernetes上的针对请求的扩展功能,
声明式API是Kubernetes的编码方式。
https://digital.ai/learn/devsecops-periodic-table/
持续交付:发布可靠软件的系统方法
[英] Jez Humble, David Farley
- 软件发布应该是一个快速且可重复的过程。
- 从“决定做某种修改”到“该修改结果正式上线”的这段时间称为周期时间(cycle time)。
- 将软件发布到生产环境的过程是一种手工密集型的、易出错且高风险的过程。
- 敏捷宣言的第一原则:“我们的首要任务是尽早持续交付有价值的软件并让客户满意。”
- 对于成功的软件,首次发布只是交付过程的开始。
译者:持续交付以全面的版本控制和全面自动化为核心,通过各角色的紧密合作,力图让每个发布都变成可靠且可重复的过程。
马丁·福勒:贯穿一切的是高度自动化,让事情能够很快完成而且没有差错。
第一部分 基础篇
1 软件交付
部署流水线就是指一个应用程序从构建、部署、测试到发布这整个过程的自动化实现。
部署流水线的目标有三个。
首先,它让软件构建、部署、测试和发布过程对所有人可见,促进了合作。
其次,它改善了反馈,以便在整个过程中,我们能够更早地发现并解决问题。
最后,它使团队能够通过一个完全自动化的过程在任意环境上部署和发布软件的任意版本。
发布反模式
反模式:手工部署软件
使用相同的脚本将软件部署到各种环境上。反模式:开发完成之后才向类生产环境部署
反模式:生产环境的手工配置管
变更首先应该被提交到版本控制系统中,然后通过某个自动化过程对生产环境进行更新。
软件发布能够(也应该)成为一个低风险、频繁、廉价、迅速且可预见的过程。
如何实现目标
作为软件从业者,我们的目标是尽快地向用户交付有用的可工作的软件。
调整一下目标,即找到可以以一种高效、快速、可靠的方式交付高质量且有价值的软件的方法。
常常说软件发布像是一种艺术,但事实上,它应该是一种工程学科。
关于反馈的三个标准是很有用的:
- 每次修改都应该触发反馈流程
一个可工作的软件可分成以下几个部分:可执行的代码、配置信息、运行环境和数据。
对环境的任何修改都应该作为配置信息来管理。
反馈流程是指完全以自动化方式尽可能地测试每一次变更。 - 必须尽快接收反馈
快速反馈的关键是自动化。
人力资源是昂贵且非常有价值的,所以我们应该集中人力来生产用户所需要的新功能,尽可能快速地交付这些新功能,而不是做枯燥且易出错的工作。
部署流水线的关键目的之一就是对人力资源利用率的优化:我们希望将人力释放出来做更有价值的工作,将那些重复性的体力活交给机器来做。 - 交付团队必须接收反馈并作出反应
对于快速交付高质量的软件来说,基于持续改进的过程是非常关键的。迭代过程有助于为这类活动建立规律性。
精益制造的目标是确保快速地交付高质量的产品,它聚焦于消除浪费,减少成本。
收效
部署流水线的一个关键点是,它是一个“拉动”(pull)系统,它使测试人员、运维人员或支持服务人员能够做到自服务,即他们可以自行决定将哪个版本的应用程序部署到哪个环境中。
将配置信息放在版本控制系统中。
减少压力的关键在于拥有一个我们前面所描述的自动化部署过程,并频繁地运行它,当部署失败后还能够快速恢复到原来状态。
候选发布版本
候选发布版本(release candidate),对于代码的任何一次修改都有被发布出去的可能性。
如果在软件开发中的某个任务令你非常痛苦,那么解决痛苦的方法只有更频繁地去做,而不是回避。
软件交付的原则
为软件的发布创建一个可重复且可靠的过程
这种可重复性和可靠性来自于以下两个原则:
(1)几乎将所有事情自动化;
(2)将构建、部署、测试和发布软件所需的东西全部纳入到版本控制管理之中。将几乎所有事情自动化
自动化是部署流水线的前提条件。把所有的东西都纳入版本控制
提前并频繁地做让你感到痛苦的事内建质量
内建质量”也是戴明(精益运动的先驱之一)提出的名言之一。越早发现缺陷,修复它们的成本越低。如果在没有提交代码到版本控制之前,我们就能发现并修复缺陷的话,代价是最小的。“DONE”意味着“已发布”
任何事情要么是完成了,要么就是没完成。
一件事情的完成与否,并不是一个人能控制得了的,它需要整个交付团队共同来完成。交付过程是每个成员的责任
为了更加快速且可靠地交付有价值的软件,鼓励所有参与软件交付整个过程中的人进行更好的协作。持续改进
戴明环:计划-执行-检查-处理(PDCA)。
2 配置管理
配置管理是指一个过程,通过该过程,所有与项目相关的产物,以及它们之间的关系都被唯一定义、修改、存储和检索。
对所有内容进行版本控制;管理依赖关系。
使用版本控制
本质上来讲,版本控制系统的目的有两个:
首先,它要保留每个文件的所有版本的历史信息,并使之易于查找。这种系统还提供一种基于元数据(这些元数据用于描述数据的存储信息)的访问方式,使元数据与某个单个文件或文件集合相链接。
其次,它让分布式团队(无论是空间上不在一起,还是不同的时区)可以愉快地协作。
使用方式:
- 对所有内容进行版本控制
所讨论的有关加快发布周期和提高软件质量的所有实践,从持续集成、自动化测试,到一键式部署,都依赖于下面这个前提:与项目相关的所有东西都在版本控制库中 - 频繁提交代码到主干
一个更好的解决方案是尽量使用增量方式开发新功能,并频繁且有规律地向版本控制系统提交代码。
为了确保提交代码时不破坏已有的应用程序,有两个实践非常有效。一是在提交代码之前运行测试套件。二是增量式引入变化。我们建议每完成一个小功能或一次重构之后就提交代码。 - 使用意义明显的提交注释
依赖管理
- 外部库文件管理
- 组件管理
软件配置管理
配置信息与产品代码及其数据共同组成了应用程序。
任何改变应用程序的行为,无论修改了什么,都算是编程,即使只是修改一行配置信息。
可配置的软件并不总是像它看起来那么便宜。更好的方法几乎总是先专注于提供具有高价值且可配置程度较低的功能,然后在真正需要时再添加可配置选项。
在相临的两次部署之间,任何变更都应该作为配置项被捕获和记录,而不应该在编译或打包时植入。
获取配置信息
管理配置最有效的方法是让所有的应用程序通过一个中央服务系统得到它们所需要的配置信息。
对于应用程序访问配置信息来说,可能最简单的方法就是使用文件系统。
还有一种方式是从某个中心仓库(如关系型数据库管理系统、LDAP或某种Web服务)中获取配置信息。为配置项建模
每个配置都是一个元组,所以应用程序的配置信息由一系列的元组构成。然而,这些元组及其值取决于三方面,即应用程序、该应用程序的版本、该版本所运行的环境(例如开发环境、用户验收测试环境、性能测试环境、试运行环境或生产环境)。系统配置的测试
对于系统配置测试来说,包括以下两部分:
一是要保证配置设置中对外部服务的引用是良好的。
二是当应用程序一旦安装好,就要在其上运行一些冒烟测试,以验证它运行正常。
系统运维团队可以通过生产系统的监控平台了解每个软件应用的配置信息,并能看到每种环境中所运行的软件到底是哪一个版本。
管理配置信息的原则:
- 应该总是通过自动化的过程将配置项从保存配置信息的存储库中取出并设置好。
- 对每个配置项都应用明确的命名习惯,避免使用晦涩难懂的名称,使其他人不需要说明手册就能明白这些配置项的含义。
- 确保配置信息是模块化且封闭的,使得对某处配置项的修改不会影响到那些与其无关的配置项。
- DRY(Don’t Repeat Yourself)原则。定义好配置中的每个元素,使每个配置元素在整个系统中都是唯一的,其含义绝不与其他元素重叠。
- 最少化,即配置信息应尽可能简单且集中。除非有要求或必须使用,否则不要新增配置项。
- 避免对配置信息的过分设计,应尽可能简单。
- 确保测试已覆盖到部署或安装时的配置操作。检查应用程序所依赖的其他服务是否有效,使用冒烟测试来诊断依赖于配置项的相关功能是否都能正常工作。
环境管理
没有哪个应用程序是孤岛。
任何变更在上线之前都必须经过测试。
环境的配置和应用程序的配置同样重要。
高效配置管理策略的两个基本原则是:
(1)将二进制文件与配置信息分离;
(2)将所有的配置信息保存在一处。
好的软件应该有一个能通过命令行执行的安装程序且不需要任何用户干预。应用程序的配置可以通过版本控制系统来管理,而且不需要手工干预。
3 持续集成
实现持续集成
持续集成要求每当有人提交代码时,就对整个应用进行构建,并对其执行全面的自动化测试集合。
持续集成不是一种工具,而是一种实践。
在开始做持续集成之前,你需要做三件事情:
- 版本控制
- 自动化构建
- 团队共识
持续集成的前提条件
- 频繁提交
- 创建全面的自动化测试套件
有三类测试会在持续集成构建中使用:- 单元测试用于单独测试应用程序中某些小单元的行为(比如一个方法、一个函数,或一小组方法或函数之间的交互)。
- 组件测试用于测试应用程序中几个组件的行为。
- 验收测试的目的是验证应用程序是否满足业务需求所定义的验收条件。
- 保持较短的构建和测试过程
- 管理开发工作区
“最新的正确版本”是指那个在持续集成服务器上最近一次通过所有自动化测试的那个版本。
使用持续集成软件
本质上,持续集成软件包括两个部分:
第一部分是一个一直运行的进程,它每隔一定的时间就执行一个简单的工作流程。
第二部分就是提供展现这个流程运行结果的视图,通知你构建和测试成功与否,让你可以找到测试报告,拿到生成的安装文件等。
必不可少的实践
构建失败之后不要提交新代码
提交前在本地运行所有的提交测试,或者让持续集成服务器完成此事
预测试提交(pretested commit),也称为个人构建(personal build)或试飞构建(preflight build)等提交测试通过后再继续工作
在提交代码时,做出了这一代码的开发人员应该监视这个构建过程,直到该提交通过了编译和提交测试之后,他们才能开始做新任务。在这短短几分钟的提交阶段结束之前,他们不应该离开去吃午饭或开会,而应密切注意构建过程并在提交阶段完成的几秒钟内了解其结果。如果真的能优化达到几分钟甚至几秒钟也行,但凡需要等个半小时就都是在浪费时间和生命
回家之前,构建必须处于成功状态
时刻准备着回滚到前一个版本
在回滚之前要规定一个修复时间
不要将失败的测试注释掉
为自己导致的问题负责
测试驱动的开发
只有非常高的单元测试覆盖率才有可能保证快速反馈(这也是持续集成的核心价值)。
推荐的实践
- 极限编程开发实践
重构是指通过一系列小的增量式修改来改善代码结构,而不会改变软件的外部行为。 - 若违背架构原则,就让构建失败
- 若测试运行变慢,就让构建失败
- 若有编译警告或代码风格问题,就让测试失败
分布式团队
技术角度上看,最为简单的方法(也是从流程角度上讲最有效的方法)就是使用共享的版本控制系统和持续集成系统。
使用持续集成的目的就是能够更早发现问题。
对于分布式团队来说,主要有两种方式来解决本地化版本控制系统的存取问题:
一是将应用程序分成多个组件;
二是使用那些分布式或支持多主库拓扑结构的版本控制系统。
分布式版本控制系统
DVCS = Distributed Version Control System 分布式版本控制系统
DVCS的核心特性是每个仓库都包括项目的完整历史,这意味着除了团队约定之外,仓库是没有权限控制功能的。
所以,与集中式系统相比,DVCS引入了一个中间层:在本地工作区的修改必须先提交到本地库,然后才能推送到其他仓库,而更新本地工作区时,必须先从其他仓库中将代码更新到本地库。
持续集成再向前一步,就是Martin Fowler所说的“随性集成”.
持续集成创建了一个快速的反馈环,使你能尽早地发现问题,而发现问题越早,修复成本越低。
持续集成的实施还会迫使你遵循另外两个重要的实践:良好的配置管理和创建并维护一个自动化构建和测试流程。
4 测试策略的实现
戴明14条之一就是:“停止依赖于大批量检查来保证质量的做法。改进过程,从一开始就将质量内嵌于产品之中。”
质量内嵌是指从多个层次(单元、组件和验收)上写自动化测试,并将其作为部署流水线的一部分来执行,即每次应用程序的代码、配置或环境以及运行时所需软件发生变化时,都要执行一次。
质量内嵌还意味着,你要不断地改进自动化测试策略。
测试策略的设计主要是识别和评估项目风险的优先级,以及决定采用哪些行动来缓解风险的一个过程。
一个全面的自动化测试套件甚至可以提供最完整和最及时的应用软件说明文档,这个文档不仅是说明系统应该如何运行的需求规范,还能证明这个软件系统的确是按照需求来运行的。
测试分类
测试用具(test harness)
软件开发是一个很自然的迭代过程,它建立在一个有效的反馈环之上,而我们却骗自己是否有其他方式来预见它。
测试象限图,由Brian Marick基于当时流行的思想提出。
验收测试确保用户故事的验收条件得到满足。
验收测试可以测试系统特性的方方面面,包括其功能(functionality)、容量(capacity)、易用性(usability)、安全性(security)、可变性(modifiability)和可用性(availability)等。
验收测试分为两类:功能测试和非功能测试。非功能测试是指除功能之外的系统其他方面的质量,比如容量、可用性、安全性等。
时新的自动化功能测试工具,比如 Cucumber、JBehave、Concordion以及Twist,都旨在把测试脚本与实现分离,以达到这种理想状态,并提供某种机制方便地将二者进行同步。
对于每个需求或用户故事来说,根据用户执行的动作,一定会找到应用程序中一个中规中矩的执行路径,这称为Happy Path。Happy Path通常以如下方式来描述:“假如[当测试开始时,系统所处状态的一些重要特征 ],当[用户执行某些动作后 ],那么[系统新的状态的一些重要特征 ]。”有时这称为测试的“given-when-then”书写模型。
回归测试是自动化测试的全集。它们用来确保任何修改都不会破坏现有的功能,还会让代码重构变得容易些,因为可以通过回归测试来证明重构没有改变系统的任何行为
一般我们将代码覆盖率高于80%的测试视为“全面的”测试。
一个很好的经验法则就是,一旦对同一个测试重复做过多次手工操作,并且你确信不会花太多时间来维护这个测试时,就要把它自动化。
单元测试用于单独测试一个特定的代码段。
单元测试不应该访问数据库、使用文件系统、与外部系统交互。或者说,单元测试不应该有系统组件之间的交互。
组件测试用于测试更大的功能集合,因此可能会捕获这类问题。当然,它们的运行通常会慢一些,因为它们要涉及更多的准备工作并执行更多的I/O操作,需要连接数据库、文件系统或其他系统等。有时候组件测试称作“集成测试”,
部署测试用于检查部署过程是否正常。换句话说,就是应用程序是否被正确地安装、配置,是否能与所需的服务正确通信,并得到相应的回应。
探索性测试被James Bach描述为一种手工测试,他说:“执行测试的同时,测试人员会积极地控制测试的设计并利用测试时获得的信息设计新的更好的测试。”探索性测试是一个创造性的学习过程,并不只是发现缺陷,它还会致使创建新的自动化测试集合,并可以用于覆盖那些新的需求。
易用性测试是为了验证用户是否能很容易地使用该应用软件完成工作。
有几种不同的方法做易用性测试,比如,情景调查,让用户坐在你的软件前面,观察他们执行常见任务的情形。
自动化测试的一个关键是在运行时用一个模拟对象来代替系统中的一部分,这样的模拟对象常常就是mock、stub和dummy等。
测试替身(test double),并进一步区分了各种测试替身:
- 哑对象(dummy object)是指那些被传递但不被真正使用的对象。通常这些哑对象只是用于添充参数列表。
- 假对象(fake object)是可以真正使用的实现,但是通常会利用一些捷径,所以不适合在生产环境中使用。一个很好的例子是内存数据库。
- 桩(stub)是在测试中为每个调用提供一个封装好的响应,它通常不会对测试之外的请求进行响应,只用于测试。
- spy是一种可记录一些关于它们如何被调用的信息的桩。这种形式的桩可能是记录它发出去了多少个消息的一个电子邮件服务。
- 模拟对象(mock)是一种在编程时就设定了它预期要接收的调用。如果收到了未预期的调用,它们会抛出异常,并且还会在验证时被检查是否收到了它们所预期的所有调用。
应对策略
在正确的时机写测试会产出更好的代码。
引入自动化测试最好的方式是选择应用程序中那些最常见、最重要且高价值的用例为起点。
集成测试是指那些确保系统的每个独立部分都能够正确作用于其依赖的那些服务的测试。
遗留系统是没有自动化测试的系统。
流程缺陷
缺陷分为严重(critical)、阻塞(blocker)、中(medium)和低(low)四个级别。
第二部分 部署流水线
持续集成的主要关注对象是开发团队。
持续集成系统的输出通常作为手工测试流程和后续发布流程的输入。
5 部署流水线解析
部署流水线的目的是,让软件交付过程中的每个人都能够看到每个构建版本从提交到发布的整个过程。
关键还是在于创建一个记录系统,用来管理从提交到发布的任何变更,为你提供在流程中尽早发现问题所需要的信息。
简介
部署流水线是指软件从版本控制库到用户手中这一过程的自动化表现形式。
流水线的输入是版本控制中的某个具体版本。
对所有项目有一些阶段是共同具有的:
- 提交阶段是从技术角度上断言整个系统是可以工作的。这个阶段会进行编译,运行一套自动化测试(主要是单元级别的测试),并进行代码分析。
- 自动化验收测试阶段是从功能和非功能角度上断言整个系统是可以工作的,即从系统行为上看,它满足用户的需要并且符合客户的需求规范。
- 手工测试阶段用于断言系统是可用的,满足了它的系统要求,试图发现那些自动化测试未能捕获的缺陷,并验证系统是否为用户提供了价值。这一阶段通常包括探索性测试、集成环境上的测试以及UAT(User Acceptance Testing,用户验收测试)。
- 发布阶段旨在将软件交付给用户,既可能是以套装软件的形式,也可能是直接将其部署到生产环境,或试运行环境(这里的试运行环境是指和生产环境相同的测试环境)。
部署流水线就是由上述这些阶段,以及为软件交付流程建模所需的其他阶段组成,有时候也称为持续集成流水线、构建流水线、部署生产线或现行构建(living build)。无论把它叫做什么,从根本上讲,它就是一个自动化的软件交付流程。
一定要记住,我们所做的这一切都是为了尽快得到反馈。为了加速这个反馈循环,就必须能够看到每个环境中都部署了哪个版本,每个构建版本在流水线中处于哪个阶段。
相关实践
- 只生成一次二进制包
第一个原则就是“保证部署流水线的高效性,使团队尽早得到反馈”。
第二原则就是“始终在已知可靠的基础上进行构建”。 - 对不同环境采用同一部署方式
- 对部署进行冒烟测试
- 向生产环境的副本中部署
系统升级过程中需要进行的数据迁移是部署活动的一个痛点 - 每次变更都要立即在流水线中传递
- 只要有环节失败,就停止整个流水线
自动化验收测试
单元测试仅仅是从开发人员的角度测试某个问题的解决方案。对于验证应用程序是否以用户期望的方式运行,单元测试的能力有限。
验收测试阶段的目标是断言应用程序交付了客户期望的价值,并满足了验收条件。
开发人员必须能在自己的开发环境中运行自动化验收测试。
实现部署流水线
建立一个完整流水线的策略。一般来说,步骤是这样的:
- 对价值流建模,并创建一个可工作的简单框架;
- 将构建和部署流程自动化;
- 将单元测试和代码分析自动化;
- 将验收测试自动化;
- 将发布自动化。
构建过程的输入是源代码,输出结果是二进制包。
二进制包的关键特征是“你能将它复制到一台新机器上(上面没有IDE等开发工具集),只要环境配置正确,且又有应用在该环境中所需的正确配置信息,它就可以启动并运行了,而不必依赖于在这台机器上安装的开发工具链的任何部分。
对于流水线来说,还有两个常见的外延:组件和分支。
一定要记住三件事:
首先,并不需要一次实现整个流水线,而应该是增量式实现。
其次,部署流水线是构建、部署、测试和发布应用程序整个流程中有效的,也是最重要的统计数据来源。
最后,部署流水线是一个有生命的系统。随着不断改进交付流程,部署流水线也应该不断变化,加以改善和重构,就像改善和重构要交付的应用一样。
全局度量
反馈是所有软件交付流程的核心。改善反馈的最佳方法是缩短反馈周期,并让结果可视化。
对于软件交付过程来说,最重要的全局度量指标就是周期时间(cycle time)。它指的是从决定要做某个特性开始,直到把这个特性交付给用户的这段时间。
6 构建部署脚本化
“脚本”这个术语被广泛应用,通常是指辅助我们进行构建、测试、部署和发布应用程序的所有自动化脚本。
脚本应该是系统中的“一等公民”。这些脚本应该贯穿应用程序的整个生命周期。我们应该对这些脚本进行版本控制、维护、测试和重构,并且将其用作部署应用程序的唯一机制。
构建工具
所有构建工具都有一个共同的核心功能,即可以对依赖关系建模。在执行过程中,它能以正确的顺序执行一系列的任务,计算如何达到你所指定的目标,而且被依赖的任务也仅需要运行一次。
每个任务都包括两点内容,一是它做什么,二是它依赖于什么。
各构建工具的不同点在于它是任务导向的,还是产品导向的:
- 任务导向的构建工具(比如Ant、NAnt和MSBuild)会依据一系列的任务描述依赖网络。
任务导向的构建工具在构建之间并不保存状态。 - 产品导向的工具,比如Make,是根据它们生成的产物(比如一个可执行文件)来描述。
面向产品的构建工具将状态以时间戳的形式保存在每个任务执行后生成的文件中(SCons使用MD5签名)。这在编译C或C++程序时非常好,因为Make会保证只编译那些自上次构建后发生过修改的源代码文件。在大型项目中,这种特性(称为增量式构建)会比全量构建节省数小时。
原则与实践
- 为部署流水线的每个阶段创建脚本
- 使用恰当的技术部署应用程序
- 使用同样的脚本向所有环境部署
- 使用操作系统自带的包管理工具
- 确保部署流程是幂等的(Idempotent)
- 部署系统的增量式演进
项目结构
Maven标准目录结构,最重要的贡献之一就是引入了项目代码结构的标准惯例。
一个典型的源代码结构如下所示:
/[project-name]
README.txt
LICENSE.txt
/src
/main
/java Java source code for your project
/scala If you use other languages, they go at the same level
/resources Resources for your project
/filters Resource filter files
/assembly Assembly descriptors
/config Configuration files
/webapp Web application resources
/test
/java Test sources
/resources Test resources
/filters Test resource filters
/site Source for your project website
/doc Any other documentation
/lib
/runtime Libraries your project needs at run time
/test Libraries required to run tests
/build Libraries required to build your project构建系统最终应该生成JAR、WAR和EAR这种形式的二进制包,并将其放在制品库的target目录中。
创建多个JAR文件的目的有两个:
- 一是令应用程序的部署更简单;
- 二是令构建流程更加高效,并将构建依赖图的复杂性最小化。这些是应用程序打包的指导方针。
部署脚本化
环境管理的核心原则之一就是:对测试和生产环境的修改只能由自动化过程执行。
有三种方法做远程部署:
- 第一种方法就是写个脚本,让它登录到每台机器上,运行适当的命令集。
- 第二种方法是写个本地运行的脚本,在每台远程机器上安装一个代理(agent),由代理在其宿主机上本地运行该脚本。
- 第三种方法就是利用操作系统自身的包管理技术打包应用程序,然后利用一些基础设施管理或部署工具拿到新版本,运行必要的工具来初始化你的中间件。
对于软件交付或某个复杂系统的构建和部署,假如说有一个基础的核心原则的话,那就是应该总是把根基扎在已知状态良好的基础之上。
常见策略
常见构建和部署问题的一些解决方案和策略:
- 总是使用相对路径
- 消除手工步骤
我们什么时候应该考虑将流程自动化呢?最简单的回答就是:“当你需要做第二次的时候。”到第三次时就应该采取行动,通过自动化过程来完成这件工作了。 - 从二进制包到版本控制库的内建可追溯性
- 不要把二进制包作为构建的一部分放到版本控制库中
- “test”不应该让构建失败
- 用集成冒烟测试来限制应用程序
7 提交阶段
提交阶段都是部署流水线的入口。
原则和实践
- 提供快速有用的反馈
- 何时令提交阶段失败
- 精心对待提交阶段
- 让开发人员也拥有所有权
- 在超大项目团队中指定一个构建负责人
提交测试套件
提交测试中,绝大部分应由单元测试组成。
单元测试最重要的特点:
- 运行速度非常快。
- 它们应覆盖代码库的大部分(经验表明一般为80%左右),让你有较大的信心,能够确定一旦它通过后,应用程序就能正常工作。
运行的单元测试不应该与文件系统、数据库、库文件、框架或外部系统等打交道。所有对这些方面的调用都应该用测试替身代替,比如模拟对象(mock)和桩等。
单元测试的目标就是要证明:应用程序的某个单一部分的确是按开发人员的思路运行的,但这并不能断言它也就是用户想要的功能。
提交测试套件的原则与实践:
- 避免用户界面
- 使用依赖注入
- 避免使用数据库
- 在单元测试中避免异步
最简单的办法就是通过测试的切分来避免异步,这样就能做到:一个测试运行到异步点时,切分出来的另一个测试再开始执行。 - 使用测试替身
打桩是指利用模拟代码来代替原系统中的某个部分,并提供已封装好的响应。桩并不对外界作出响应。
现在有几种模拟技术工具集,比如Mockito、Rhino、EasyMock、JMock、NMock和Mocha等。使用模拟技术,你就可以说:“给我构建一个对象,让它假装就是某某类型的一个类。” - 最少化测试中的状态
理想情况下,单元测试应聚焦于断言系统的行为。 - 时间的伪装
- 蛮力
计算能力是廉价的,而人力是昂贵的。
8 自动化验收测试
验收测试通常是在每个已通过提交测试的软件版本上执行的。
验收测试是针对业务的,而不是面向开发的。
对于一个单独的验收测试,它的目的是验证一个用户故事或需求的验收条件是否被满足。
验收条件有多种类型,如功能性验收条件和非功能性验收条件。
非功能性验收条件包括容量(capacity)、性能(performance)、可修改性(modifiability)、可用性(availability)、安全性(security)、易用性(usability),等等。其中的关键点在于,当与某个具体用户故事或需求相关的验收测试成功后,就表明这个用户故事或需求已满足验收条件,可以认为它已完成并且是可正常工作的。
拒绝未能通过验收测试的候选发布版本”这一纪律是交付团队开发高质量软件过程中前进的一大步。
人类生来就不适合做那种索然无味的、需要不断重复但却非常复杂的工作。
有效性
有效自动化验收测试的创建和维护问题,包括(1)创建验收测试;(2)创建应用程序驱动层;(3)实现验收测试;(4)维护验收测试套件。
INVEST原则是关于用户故事的定义和拆分的一系列准则,它包括以下几个关键要素:
- 独立性(Independent):用户故事应尽可能独立,减少对其他故事的依赖,这样有助于优先级对齐、发布和迭代计划,以及独立理解、跟踪、实施、测试和频繁交付。独立性有助于使故事大小估计更清晰,减少估计偏差。
- 可协商性(Negotiable):用户故事的内容应是可协商的,不是固定的合同。用户故事描述应简洁,缺乏太多细节,具体细节应在沟通阶段产生。过多的细节可能限制想法和沟通。
- 有价值(Valuable):每个用户故事都必须对客户有价值,应从用户角度编写,描述功能而非任务。这有助于团队成员理解他们工作的价值。
- 可估计性(Estimable):在计划会议中,应对用户故事的复杂性进行粗略估计,以便团队了解故事的复杂性(工作量)。确保故事在当前迭代中是否可完成,不能完成时应拆分或重新设计。
- 短小性(Small):用户故事在工作量上应尽可能短小,最好不超过10个理想人/天,至少要保证一次迭代完成。故事越大,调度和估计风险越大。
- 可测试性(Testable):用户故事应该是可测试的,以确认它是否完成。不可测试的故事无法知道何时完成。
这些原则不仅用于定义和拆分用户故事,也可以用于控制迭代的准入,确保每个迭代中的用户故事都是独立、可协商、有价值、可估计、短小且可测试的。
创建验收测试
验收测试就是正在开发的应用程序行为的一个可执行规格说明书。
这作为自动化测试的一种新方法,被称为行为驱动开发。
行为驱动开发的核心理念之一就是验收测试应该以客户期望的应用程序行为的方式来书写。
Chris Matts和Dan North总结出一种写验收测试的领域特定语言,其格式如下:假如(Given)初始条件,当(When)某个事件发生时,那么(Then)就会有……结果。
对应用程序来说,
“假如”表示在测试用例开始之前应用程序所处的状态。
“当……”描述用户与应用程序间的一个交互动作。
“那么……”描述交互完成后,应用程序所处的状态。
测试用例的工作就是让应用程序达到“假如”中所述的状态,然后执行“当……”中所描述的动作,最后验证应用程序是否处于“那么”中所描述的状态。
创建可执行规格说明的方法是行为驱动设计的本质。
回顾一下这个过程:
- 和客户一起讨论用户故事的验收条件;
- 以可执行的格式将得到的验收条件写下来;
- 为这些使用领域专属语言所描述的测试写出它的代码实现,与应用程序驱动层进行交互。
- 创建应用程序驱动层,使测试通过它来与系统交互。
传统方式(比如使用Word文档或者跟踪工具来管理验收条件,或者使用录制回放方式创建验收测试)
应用程序驱动层
验收测试分为三层:可执行的验收条件、测试实现和应用程序驱动器层。
应用程序驱动器层中与GUI交互的这部分就叫做窗口驱动器。
应用程序驱动器与窗口驱动器的区别在于:窗口驱动器知道如何与GUI打交道。
应用程序驱动层是一个知道如何与应用程序(即被测试的系统)打交道的层次。
应用程序驱动层所用的API是以某种领域语言表达的,可以认为是一种针对它自己的领域专属语言。
DSL(Domain-Specific Language,领域专属语言)是一种计算机编程语言,用于解决某个具体问题域的某个问题。
它与通用编程语言不同,因为它无法像通用编程语言那样可以解决很多类型的问题,它专门为解决某个专属问题域的问题而设计。
DSL可以分为两种类型:内部的和外部的。
内部DSL是那种直接在代码中表达的。
外部的领域专属语言在其指令被执行之前需要明确的解析。
实现验收测试
最理想的测试应该具有原子性。原子测试是指测试的执行顺序无关紧要,这样就消除了那些很难追踪的bug的主要来源之一。而且,这也意味着测试可以并行执行。
验收测试最有效的方法是:利用应用程序自身的功能特性来隔离测试的范围。
真正的解决方案是,只要能依赖系统自身的真正行为来验证测试的结果,就尽量避免这种妥协。
管理异步与超时问题,最有效的策略是构建一个夹具用于将测试本身与这个问题隔离开来。诀窍是,对于测试本身而言,让事件顺序发生,使测试看起来像是同步的。
自动化验收测试不应该运行在包含所有外部系统集成点的环境中。相反,应该为自动化验收测试提供一个受控环境,并且被测系统应该能在这个环境上运行。“受控”是指,可以为每个测试创建正确的初始化状态。
验收测试阶段
让失败可视化。
最好的验收测试是具有原子性的,即它们创建自己的起始条件,并在结束时将环境清理干净。
验收测试的性能
- 重构通用任务
最显而易见且快速奏效的方法就是每次构建结束后都找到最慢的几个测试,再花上一点儿时间找些办法让它们更加高效。 - 共享昂贵资源
- 并行测试
- 使用计算网格
9 非功能需求的测试
NFR(NonFunctional Requirement,非功能需求)
“性能”是对处理单一事务所花时间的一种度量,既可以单独衡量,也可以在一定的负载下衡量。
“吞吐量”是系统在一定时间内处理事务的数量,通常它受限于系统中的某个瓶颈。在一定的工作负载下,当每个单独请求的响应时间维持在可接受的范围内时,该系统所能承担的最大吞吐量被称为它的容量。
非功能需求的管理
软件工程协会(Software Engineering Institute)的ATAM(Architectural Tradeoff Analysis Method,架构权衡分析方法)就是通过对系统非功能需求(称为“质量属性”)进行完整分析,帮助团队选择一种合适的架构。
容量编程
在找到解决方案之前,必须先找出问题的根源。也就是说,我们要知道问题到底是什么。
过早且过分地关注应用程序的容量优化是低效且昂贵的。
生产环境是唯一真实度量的来源。
容量度量
基准式(benchmark-style)
假阳性(false-positive)
容量度量要广泛研究应用程序的特征。比如,可以做如下的度量:
- 扩展性测试。随着服务器数、服务或线程的增加,单个请求的响应时间和并发用户数的支持会如何变化。
- 持久性测试。这是要长时间运行应用程序,通过一段时间的操作,看是否有性能上的变化。这类测试能捕获内存泄漏或稳定性问题。
- 吞吐量测试。系统每秒能处理多少事务、消息或页面点击。
- 负载测试。当系统负载增加到类似生产环境大小或超过它时,系统的容量如何?这也许是最典型的容量测试。
自动化容量测试
高容量系统(high-volume system)
对于系统的可扩展性测试来说,有一种有效的方法,如Nygard所述:“识别出系统中代价最高的事务,然后在系统中把它变成两三倍的数量”。
防卫测试 guard test
要一直遵守这样的格言,即做最少的工作达到我们的目标,这也是YAGNI(“You Ain’t Gonna Need It”)原则所暗示的。
YAGNI提醒我们,增加防御性行为都有可能成为浪费。
如果遵循高德纳的格言,应该直到明确需要优化而且到了最后时刻才做优化。
另外,还要基于应用程序运行时分析结果,直接解决最重要的瓶颈问题。
10 应用程序的部署与发布
部署与发布之间的主要区别在于回滚的能力。
降低发布风险的最佳方法是真正地做发布演练。
部署回滚和零停机发布
通过重新部署原有的正常版本来进行回滚
零停机发布(也称为热部署),是一种将用户从一个版本几乎瞬间转移到另一个版本上的方法。
零停机发布的关键在于将发布流程中的不同部分解耦,尽量使它们能独立发生。蓝绿部署
对于发布管理来说,蓝绿部署是我们所知道的最强大的技术之一。做法是有两个相同的生产环境版本,一个叫做“蓝环境”,一个叫做“绿环境”。金丝雀发布就是把应用程序的某个新版本部署到生产环境中的部分服务器中,从而快速得到反馈。就像发现一只煤矿坑道里的金丝雀那样,很快就会发现新版本中存在的问题,而不会影响大多数用户。这是一个能大大减少新版本发布风险的方法。
紧急修复
任何情况下,都不能破坏流程。
紧急修复版本也要走同样的构建、部署、测试和发布流程,与其他代码变更没什么区别。
因为我们看到过很多场合,修复版本直接被放到生产环境中,而产生一个未受控版本。
持续部署
遵循极限编程的座右铭:如果它令你很受伤,那么就做更多的练习(If it hurts, do it more often)。
客户端处理升级有如下几种方式:
(1)让软件自己检查是否有新版本,并提示用户下载并升级到最新版本。这是最容易实现的,但用起来也是最痛苦的。没人想看着一个下载进度条一点一点地向前走。
(2)在后台下载,并提醒用户安装。在这种模式中,软件需要周期性地检查更新,在运行的同时悄悄地下载。当下载成功后,不断地提醒用户升级到最新版本。
(3)在后台下载并在应用程序下次启动时悄悄升级。应用程序可能也会提示你立即重新启动(Firefox就是这么做的)。
小贴士
- 真正执行部署操作的人应该参与部署过程的创建
- 记录部署活动
- 不要删除旧文件,而是移动到别的位置
在UNIX环境中,一个最佳实践是:把应用程序的每个版本部署在一个单独目录中,用一个符号链接指向当前版本。 - 部署是整个团队的责任
- 服务器应用程序不应该有GUI
- 为新部署留预热期
- 快速失败
- 不要直接对生产环境进行修改
第三部分 交付生态圈
11 基础设施和环境管理
运维团队的需要
强调合作是DevOps运动的核心原则之一。
DevOps运动的目标是将敏捷方法引入到系统管理和IT运营世界中。
这场运动的另一个核心原则是,利用敏捷技术对基础设施进行有效管理。
可恢复性(recoverability)、可支持性(supportability)和可审计性(auditability)。
运维团队最为重要的关注点:
- 文档与审计
所有的项目干系人都能达成一个共识,即让发布有价值的软件成为一件低风险的事情。
最佳方法就是尽可能频繁地发布(即持续交付)。 - 异常事件的告警
RPO(Recovery Point Objective,恢复点目标,即灾难之前丢失多长时间内的数据是可接受的)
RTO(Recovery Time Objective,恢复时间目标,即服务恢复之前允许的最长停机时间)
RPO控制了数据备份和恢复策略,因为数据备份必须足够频繁,才能达到这个RPO。 - 使用运维团队熟悉的技术
基础设施的访问控制
基础设施的配置管理:
- 操作系统的安装定义项(比如使用的Debian Preseed、RedHat Kickstart和Solaris Jumpstart)。
- 数据中心自动化工具的配置信息,比如Puppet或CfEngine。
- 通用基础设施配置信息,比如DNS 区域文件(zone file)、DHCP和SMTP服务器 配置文件、防火墙配置文件等。
- 用于管理基础设施的所有脚本。
服务器的准备与配置管理
良好的变更管理的关键在于创建一个自动化流程,从版本控制库中取出基础设施的变更项进行部署。如果想做到这一点,最有效的方法是要求所有对环境的修改都要通过一个集中式系统。
“艺术工作”:一种手工的,只有专家才能做的工作。
PXE(Preboot eXecution Environment)
WDS(Windows Deployment Services)
- 服务器的准备
创建操作系统基线有如下几种方法:
- 完全手工过程。
- 自动化的远程安装。
- 虚拟化。
- 服务器的持续管理
为了配置一下后 从WDS启动,需要准备两个映像:一个启动映像和一个安装映像。
启动映像是由PXE加载到RAM的在Windows上,有个软件叫作WinPE(Windows Preinstallation Environment)
这个安装光盘是一个自启动的完整安装盘,它会把映像加载到机器上。从Vista以后,这两个映像都在DVD安装盘的源目录下,叫做BOOT.WIM和INSTALL.WIM。
在Windows上,除了WDS,微软还为管理微软基础设施提供了另一个解决方案:SCCM(System Center Configuration Manager,系统中心配置管理器)。
SCCM使用ActiveDirectory和Windows Software Update Services来管理操作系统的配置,包括组织中每台机器的更新和设置。
使用与ActiveDirectory集成的Group Policy来管理访问控制,自Windows 2000以后,它就被打包在所有的微软服务器上了。
而在UNIX世界里,LDAP通常是UNIX进行访问控制的工具,用于控制谁在哪台机器上能做什么。
大多数开源工具来说,环境配置信息都保存在一系列的文本文件中,而这些文本文件都保存在版本控制库中。
也就是说,基础设施的配置信息是自我描述的(self-documenting),即想看配置信息的话,直接到版本控制库中就可以查到。
而商业工具通常都会使用数据库来管理配置信息,并且需要通过UI来编辑它。
中间件的配置管理
无论是Web服务器、消息系统,还是商业套装软件,这些中间件都可以被分成三部分内容:二进制安装包、配置项以及数据。
通常,在脚本化配置这方面,走在前面的往往是开源的系统和组件。
“痛苦注册表”(pain-register),即每天因低效技术而损失的时间。
虚拟化
虚拟化是一种在一个或多个计算机资源上增加了一个抽象层的技术。
平台虚拟化是指模拟一个完整的计算机系统,从而在单个物理机上同时运行多个操作系统的实例。在这种配置中,有某种VMM(Virtual Machine Monitor,虚拟机监控器)或hypervisor,完全控制物理机的硬件资源。运行在虚拟机之上的Guest操作系统由VMM管理。
环境虚拟化包括模拟一台或多台虚拟机以及它们之间的网络连接。
虚拟化还提供了下列收益:
- 对需求的变化作出快速响应。
- 固化
- 硬件标准化。
- 基线维护更容易。
- 虚拟化技术提供了一个简单的机制来创建系统所需的环境基线。
- 容易将任何环境恢复到原有状态
- 创建生产环境的副本变得更容易
- 它是实现真正的一键部署应用程序任意版本的最后一部分。
- VMM提供了对系统某些方面的编程控制方式,比如网络连接。
- 提供了显著加快运行时间较长的那些测试。
虚拟机技术的最重要特性之一就是一个虚拟机映像只是一个文件。这个文件叫做“磁盘映像”。
虚拟化还能让另外两种不可追踪的场景更容易管理:(1) 已经用非受控方式修改过的环境,(2) 无法以自动化方式来管理栈中的软件。
部署流水线的目的是,对应用程序做的每个修改都能通过自动化构建、部署和测试过程来验证它是否满足发布要求。
云计算
效用计算(utility computing)。它是指像家中的电力和燃气一样,把计算资源(如CPU、内存、存储和带宽)也作为一种计量服务方式来提供。
云计算中,信息存储在因特网中,并通过因特网上的软件服务进行读取和使用。
云计算的特征是:通过扩展所使用的计算资源(比如CPU、内存、存储等)来满足需求,而只需要为自己所使用的这些资源付费就行了。
云计算既包括它所提供的软件服务本身,也包括这些软件所用到的软硬件环境。
云计算的大体上分为三类:云中的应用、云中的平台和云中的基础设施。
- 云中的应用指像WordPress、SalesForce、Gmail和Wikipedia这样的软件服务,即将传统的基于Web的服务放到云基础设施上。
- 云中平台的例子包括一些服务,比如Google App Engine和Force.com,服务供应商给你提供了一个标准的应用栈来使用。
- 云中基础设施是最高层次的可配置性,比如AWS。
打算迁移到云基础设施的人会提出两个非常重要的问题:安全问题和服务级别问题。
本质上来说,这也意味着你的应用和你的数据最终都在供应商的掌握中。
收集数据
MIB (Management Information Base,一种可扩展的数据库格式)
监控数据的来源可能有以下几个:
- 硬件,通过带外管理(out-of-band management,也被称为LOM(Lights-Out Management,远端控制管理)。
几乎所有的现代服务器硬件都实现了IPMI (Intelligent Platform Management Interface,智能平台管理接口),让你可以监控 电压、温度、系统风扇速度、peripheral health,等等,还要执行一些活动,比 如反复开关电源或点亮前面板的指示灯,即使机器已经关机了。 - 构成基础设施的那些服务器上的操作系统。
所有操作系统都提供接口以得到性 能信息,比如内存使用、交换空间(SWAP)的使用、磁盘空间、I/O 带宽(每 个磁盘和NIC)、CPU使用情况,等等。
通过监控进程表来了解每个进程所用的 资源也是非常有用的。
在UNIX上,“收集”(Collectd)是一个标准方法来收集这些数据。在Windows平台上,利用一个叫做性能计数器的系统来做这件事,它也可以被其他供应商的性能数据所使用。 - 中间件。
它可以提供资源的使用信息,如内存、数据库连接池、线程池,以及 连接数、响应时间等信息。 - 应用程序。
应用程序应该设计实现一些数据监控的钩子(hook)功能,这些数据应该是运维人员和业务人员比较关心的,比如业务交易数量、它们的价值、转换率,等等。
应用程序应该使对用户分布以及行为的分析变得很容易。它应该记录其所依赖的外部系统的连接状态。最后,如果适当的话,它还应该能 告它自己的版本号及其内部组件的版本。
有很多种方法收集数据。首先,业界有很多种工具,既有商业产品,也有开源项目。它们会在整个数据中心里收集前面提到的所有数据,存储它,生成报告、图表和信息展示板,还会提供通知机制。
领先的开源工具包括Nagios、OpenNMS、Flapjack和Zenoss,当然还有很多。
领先的商业产品是IBM的Tivoli,惠普的Operations Manager、BMC和CA。这一领域中,还有一个新进入的商业产品,那就是Splunk。
实际上,为了监控,这些产品使用了各种开放技术。最主要的是SNMP,以及它的后继者CIM和JMX(用于Java系统)。SNMP是监控领域最可敬且最常见的标准。
SNMP有三个主要组成部分:受管理的物理设备(如服务器、交换机、防火墙等物理系统),代理器(通过SNMP与那些你想监控和管理的应用或设备进行联系的代理),以及监控被管理设备的网络管理系统。
网络管理系统和代理通过SNMP协议进行通信,它是标准TCP/IP栈最顶层的一个应用层协议(application-layer protocol)。
记录日志,大多数日志系统有几个级别,比如DEBUG、INFO、WARNING、ERROR和FATAL。
12 数据管理
数据库脚本化
系统集成测试(Systems Integration Testing,SIT)
数据库的初始化和所有的迁移都需要脚本化,并提交到版本控制库中。
增量式修改
部署一份新数据库的过程如下:
- 清除原有的数据库。
- 创建数据库结构、数据库实例以及模式等。
- 向数据库加载数据。
以自动化方式迁移数据最有效的机制是对数据库进行版本控制。
管理数据库变更的技术需要达到以下两个目标:
首先,要能够持续部署应用程序而不用担心当前部署环境中所用的数据库版本。
其次,部署脚本只要将数据库向前或向后更新到与应用程序相匹配的版本即可。
技术债:
任何一个设计决定都会有一定的成本。有些成本是显而易见的,比如开发一个新功能所花的时间。有些成本却不是,比如对该功能进行维护的成本。用较差的设计方案进行系统交付,其成本通常是以系统中的bug数量来体现的。这一定会影响设计的质量,而且更重要的是增加系统维护的成本。所以“债”这种比喻十分适当。
如果我们做的设计决定是次优的,相当于我们在贷款。因为有了债,所以就会有利息。对于技术债来说,利息是以维护的成本来体现的。和金融上的债一样,当技术债积累到一定程度时,这些项目就只能偿还利息,根本无能力还本金了。这种项目只能维持它的运行,无法新增功能为所有者带来价值。
使用敏捷方法进行开发的一个原则是:通过每次修改后进行重构以便使技术债最小化,从而得以优化设计。
数据库回滚和无停机发布
管理增量修改的一种方法是让应用程序与数据库的多个版本兼容,以便数据库的迁移与依赖于它的那些应用程序相对独立。对于那种无停机发布(Zero-Downtime Release)。
生产环境的部署常见的需求会成为额外的约束:
一是当回滚时需要保留本次升级后产生的数据。
二是根据签订的SLA,要保持应用程序的可用状态,也叫做热部署或无停机发布。
第三种方法可用于管理热部署,那就是将应用程序部署过程与数据库迁移过程解耦,分别执行它们。
测试数据的管理
另一种管理数据库变更和重构的方法是以存储过程和视图的形式来使用抽象层。
最简单的方法是确保在测试结束时,总是将数据库中的数据状态恢复到该测试运行之前的状态。可以用手工方法来做,但最简单的方法是依靠大多数RDMS提供的事务特性。
总的来讲,有以下三种方法可以用来做测试设计,以便管理好数据的状态:
- 测试的独立性(test isolation):合理地组织测试,以便每个测试的数据只对该测试可见。测试独立性是指确保每个测试都具有原子性。
- 适应性测试(adaptive tests):按如下方式进行测试设计——每次运行时先对数据环境进行检查,然后使用这些检查中得到的数据作为数据基础,对系统行为进行测试。
- 测试的顺序性(test sequencing):按如下方式进行测试设计——按某种已知的序列运行,每个测试的输入依赖于前一个的输出。通常,我们强烈推荐使用第一种方法。
期望数据管理
通过测试来断言所开发的应用程序的行为符合期望的结果。
运行单元测试来避免刚做的修改破坏已有的应用程序。
运行验收测试来断言应用程序交付了用户所期望的价值。
执行容量测试来断言应用程序满足我们的容量需求。
最有效的测试不是真正的数据驱动的,它们应用使用最少的测试数据来断言被测试的单元正确完成了所期望的功能。
考虑如何为某个验收测试准备应用程序的某个状态时,区分以下三类数据是非常有用的:
- 测试的专属数据(test-specific data):那些在测试中用于驱动应用程序行为的数据。它代表了测试中这个用例的细节。
- 测试的引用数据(test reference data):这类数据通常是附加的,与某个测试相关,但是并不真正与被测试的行为相关。测试中需要它,但只是对该测试的 一个支持,而不是主角。
- 应用程序的引用数据(application reference data):经常有一类数据,它们与被测试的行为无关,但是是应用程序运行所必需的。
13 组件和依赖管理
组件,是指应用程序中的一个规模相当大的代码结构,它具有一套定义良好的API,而且可以被另一种实现方式代替。
既能让应用程序一直处于可发布状态,又能尽可能让团队高效开发的技术。原则就是确保团队尽快得到代码修改后所产生的影响。
达到这一目标的一种策略就是确保将每次修改都分解成小且增量式的步骤,并小步提交。
还有一种策略是将应用程序分解成多个组件。将应用程序分解成一组松耦合且具有良好封闭性的协作组件不只是一种好的设计。而且,对于一个大系统的开发来说,还可以提高工作效率,得到更快的反馈。
保持应用程序可发布
将新功能隐蔽起来,直到它完成为止。
为了在变更的同时还能保持应用程序的可发布,有如下四种应对策略:
- 将新功能隐蔽起来,直到它完成为止。
- 将所有的变更都变成一系列的增量式小修改,而且每次小的修改都是可发布的。
- 使用通过抽象来模拟分支(branch by abstraction)的方式对代码库进行大范围的变更。
- 使用组件,根据不同部分修改的频率对应用程序进行解耦。
所有修改都是增量式的:
- 边走边评估(take stock as you go along)
- 通过抽象来模拟分支(branching by abstraction)
依赖
Java应用程序依赖于JVM,它提供了JavaSE API的一个实现,而.NET应用程序依赖于CLR,Rails应用程序依赖于Ruby on Rails 框架,用C编写的应用程序依赖于C语言标准库,等等。
依赖区分
构建时依赖与运行时依赖之间的区别如下:
构建时依赖会出现在应用程序编译和链接时(如果需要编译和链接的话);
而运行时依赖会出现在应用程序运行并完成它的某些操作时。库管理
在软件项目中,有两种适当的方法来管理库文件:
一种是将它们提交到版本控制库中,
另一种是显式地声明它们,并使用像Maven或Ivy这样的工具从因特网上或者(最好)从你所在组织的公共库中下载。习惯上,在项目的根目录上会创建一个lib目录,所有的库文件都会放在这个目录中。
建议添加三个子目录:build、test和run,分别对应构建时、测试时和运行时的依赖。
建议在库文件名后加上版本号,作为库文件的命名规则。因此,不要只把nunit.dll签入到库目录,而应该签入nunit-2.5.5.dll。开源的制品库管理工具包括Artifactory和Nexus。
组件
大多数组件的一个显著特征是,它们会以某种方式公开其API。
这些API的技术形式可能不同:动态链接、静态链接、Web服务、文件交换(file exchange)和消息交换(message exchange),等等。
一个设计良好的代码库应该遵守DRY原则,并由遵从迪米特法则且具有良好封装性的对象组成,通常会使开发更高效、更容易。
每个构建的目录结构都应该包含单元测试、验收测试及它们所依赖的库文件、构建脚本、配置信息和其他需要放到版本库中的东西。每个组件或者组件集合的构建都应该有自己的构建流水线来证明它满足发布条件。
一个组件可能由几个二进制包组成。一般的指导原则是:应该尽量将需要管理的构建数量最少化。一个优于两个,两个优于三个,以此类推。持续优化构建,让它更高效,尽可能保持单一流水线,只有当效率太低而无法忍受时,才使用并行流水线方式。
集成流水线是每个个体组件流水线的扩展。
集成流水线的起点是:从所有组件流水线中得到组成该应用系统的二进制包。
部署流水线的两个通用原则:快速反馈和为所有相关角色提供构建状态可视化。
管理依赖关系图
Chaffee的建议是,在依赖图中引入一些新的触发类型,即某个上游依赖的触发类型包括 “静止”(static)、“慎用”(guarded)和“活跃”(fluid)。
“静止类型”的上游依赖发生变化后,不会触发新的构建。
“活跃类型”的上游依赖发生变化后就一定会触发新的构建。
如果某个“活跃类型”的上游依赖发生变更后触发了构建,并且这次构建失败了,那么就把上游依赖标记为“慎用类型”,并且将这个上游依赖的上一次成功的组件版本被标记为“好版本”。
保持较浅的依赖关系图,尽最大努力确保向后兼容(backwards compatibility)。
以某种方式对构建时的组件关系图进行强力的回归测试。
管理二进制包
制品库的最重要特性就是,它不应该包含那些无法重现的产物。
最简单的制品库是磁盘上的一个目录结构。
实现部署流水线需要做两件事:一是将构建过程中的产物放到制品库里;二是以后需要时能把它取出来。
项目中有两种依赖:外部库依赖,以及应用程序的组件间依赖。
14 版本控制进阶
“在软件开发过程中能够对所创建和依赖的资产进行有效控制”。
在一个代码基上创建分支(或流)的能力是版本控制系统最重要的特性。
三种不同的版本控制系统:标准的集中式、分布式以及基于流的模式。
一方面,从持续集成的角度来说:每次修改都应该尽早地提交到主干。主干总是处于最完整且最新的状态,因为会用它来做部署。无论使用哪种技术,或者合并工具如何强大,假如变更无法被及时提交到主干,那么时间越长,合并时的风险就越高,当最终合并时,就会越容易发生问题。
另一方面,当存在某些因素(比如网络连接不稳定、构建速度较慢或方便性)时,分支可能会更高效一些。
推荐使用分支而无须说明的唯一情况就是:为了发布或技术调研创建分支,以及在极困难的情况下没有更合适的方式通过别的方法对应用程序做进一步的修改时才创建分支。
集中式版本控制系统
分布式版本控制系统
DVCS(Distributed Version Control System,分布式版本控制系统)
现在,已经有很多有竞争力的开源DVCS了。其中,最流行且功能丰富的产品是Git(由维护Linux内核的Linus Torvalds创建,并被很多其他项目所用)、Mercurial(Mozilla Foundation、OpenSolaris和OpenJDK都在使用)和Bazaar(Ubuntu在使用)。其他开发活跃的开源DVCS包括Darcs和Monotone。
DVCS与集中式版本控制系统的主要区别在于,代码提交到本地的代码库中,相当于你自己的分支,而不是中央服务器中。
基于流的版本控制系统
基于流的版本控制系统(比如ClearCase和AccuRev)可以把一系列修改一次性应用到多个分支上,从而减少合并时的麻烦。
最大的区别在于,流之间是可以相互继承的。
这种流模式开发的问题之一就是晋升是在源代码级别完成的,而不是二进制级别。
最佳规则是尽可能频繁地晋升修改,并在开发人员所共享的流上尽可能频繁且尽可能多地运行自动化测试。
基于流的版本控制系统的卖点之一就是:开发人员很容易在自己的私有流上工作,并且还承诺,之后再做合并也很容易。
一种有用的策略是:只有当修改与部署流水线有关的流时才触发构建,而不是当变更被晋级到祖先流时就触发。
“需要做重构时就要不遗余力地做好重构”。
主干开发
在这种模式中,开发人员几乎总是签入代码到主干,而使用分支的情况极少。
主干开发有如下三个好处:
- 确保所有的代码被持续集成。
- 确保开发人员及时获得他人的修改。
- 避免项目后期的“合并地狱”和“集成地狱”。
软件需要良好的组件化、增量式开发和特性隐藏(feature hiding)。
迪米特法则(Law of Demeter)又叫作最少知识原则(Least Knowledge Principle,简写为LKP),就是说,一个对象应当对其他对象有尽可能少的了解,不和陌生人说话。英文简写为LoD。
15 持续交付管理
良好的管理所创建的流程令软件更高效地交付,同时确保风险被适当地管理,规章制定被严格遵守。
迭代增量式交付是有效风险管理的关键。
英国特许管理会计师公会(The Chartered Institute of Management Accountants),简称“CIMA”,是全球较大的管理会计师组织,同时它也是国际会计师联合会(IFAC)的创始成员之一。
CIMA 把企业治理(enterprise governance)定义为“由董事会(board)和执行管理层行使的一系列职责和实践,其目的是提供战略方向,以确保达成业务目标,风险被合理地管理起来,并验证组织的资源被可靠地使用了。
”企业治理更关注于符合度(conformance),即遵从性、保障、监管、责任和透明管理,而业务治理(businessgovernance)更关注业务和价值创造的执行度(performance)。
配置与发布管理成熟度模型
部署自动化提供了一种能力,可以做到一键式发布和回滚。
零和博弈又称零和游戏,与“非零和博弈”相对,是博弈论的一个概念,属非合作博弈,指参与博弈的各方,在严格竞争下,一方的收益必然意味着另一方的损失,博弈各方的收益和损失相加总和永远为“零”。双方不存在合作的可能。
项目生命周期
创建一个实施计划。可能最常见的方法就是先验证一下。
团队组建与磨合常常会经历五个阶段:
- 创建期(forming)指团队开始形成,团队成员开始互相了解,而不特别关注工作。这时候效率是低下的。
- 风暴期(storming)指头脑风暴,即团队成员花大量时间讨论如何领导,如何分配工作,怎样工作还有达到的目标。效率较低下。
- 规范期(norming)指团队确定了决策流程,并开始规范自己的行为,开始关注怎样工作能最好的达到目标,效率上升。
- 运转期(performing)指团队开始有效率的工作,并在工作中避免个人冲突,团员懂得怎样做决定和工作,效率很高。
- 调整/重组期(mourning/reforming)指经过一段时间的运转后,团队出现种种新的问题,进行调整和重组过程。如此循环往复。
软件也会经过几个阶段。初步可包含以下阶段:
识别阶段(identification)
启动阶段(inception)
利益干系人列表,其中最重要的是业务主要负责人(business sponsor,在PRINCE2是高级责任人)。
这个业务负责人在Scrum中叫做Product Owner,在其他敏捷形式中就是指客户。PRINCE是PRoject IN Controlled Environment(受控环境下的项目管理)的简称。
PRINCE2描述了如何以一种有逻辑的、有组织的方法,按照明确的步骤对项目进行管理。它不是一种工具也不是一种技巧,而是结构化的项目管理流程。初始阶段(initiation)
开发和部署阶段(development and deployment)
迭代开发过程的关键在于划分优先级和并行化。Scrum是一种迭代式增量软件开发过程,通常用于敏捷软件开发。包括一系列实践和预定义角色的过程框架。
Scrum在很多项目上成功了,但我们也看到过它失败。而失败的原因主要有如下三个:- 缺乏承诺。敏捷过程依赖于透明性、协作 性、纪律性和持续改进。
- 忽视好的工程实践。
- 将敏捷开发过程进行适应性调整,直到这个过程不再敏捷了。
运维阶段(operation)
常见交付问题
- 不频繁的或充满缺陷的部署
- 较差的应用程序质量
- 较差的应用程序质量
- 缺乏管理的持续集成工作流程
- 缺乏管理的持续集成工作流程
- 较差的配置管理
符合度与审计
申请审批系统(automated ticketing system)
“如果做一件事令你很痛苦,就更频繁地做这件事。”
一些原则和做法,以确保既遵守这些法规制度,又保持较短的发布周期:
文档自动化
自动化脚本就是一份必须遵守的部署流程文档。强制使用这些脚本,你就要确保它们是时时更新的,并且部署流程是完全按照你指定的方式执行的。加强可跟踪性
在筒仓中工作
缺乏合作恰恰是各部门之间交流不畅的结果。
开发软件最高效的团队是一个跨职能团队,它的成员来自于参与软件定义、开发、测试和发布软件过程中的各种角色。当实现和管理一个变更审核流程时,还需要遵守如下三个原则:
- 对系统进行度量,并让其结果可见。
- 保持验证系统成功的度量项,并将其可视化。
- 邀请各部门的代表,对系统进行定期回顾,基于这些回顾会议中的反馈对系统 进行改进。
点评:
DevOps,概言之,使开发运维自动化。
开发者,开发功能;运维者,维持稳定。
持续交付,快速反馈,迭代增量。
“我们还能与家人和朋友共度周末,享受没有压力的生活,而工作也会变得更加高效。为什么不呢?生命如此短暂,我们不能把自己的假期浪费在计算机旁,做那些枯燥无味的部署工作。”
天天学敏捷:Scrum团队转型记
[中] 杨蕾,郑江
人的本性是讨厌改变的。但是,不变即亡。
根据人类历史的经验,科技往往会走在管理的前面,但终有一天,随着规模的扩大,管理会成为制约你们发展的瓶颈。
敏捷性是要确保在错综复杂的市场环境里你具备足够的灵活性来调整自己以适应环境,即有效——做正确的事。
彼得·德鲁克:效率就是把事情做对,有效就是做正确的事。
回答4个关于敏捷和Scrum的问题:为什么?谁来做?怎么做?做什么?即Why,Who,How,What!
Scrum电子任务板功能概述:
工件是Scrum的一个专业术语,包括Scrum的所有工作项和成果。
用户故事是最常见的描述Scrum工作项的技术。因此,经常会直接将工作项称为用户故事。
任务是用户故事的子集。一个用户故事(工件)可以包括多个任务。
Why - 敏捷和Scrum
为什么敏捷
需求不明确和技术不确定这两个特点导致瀑布开发方式不能很好地工作。
- 需求不明确指的是:虽然对要做一个怎样的产品有规划,但是并不明确和确定所有功能的细节;并且随着产品的开发,极有可能对产品功能不断地改变以适应最终用户的需求。这种情况经常发生在对全新概念的产品的开发过程中。
- 技术的不确定性指的是:技术的发展日新月异,对于所定义功能的可实现性面临着多重不确定性的因素。
典型的敏捷方法,处理那些我们并没有掌握所有信息,无法控制不确定性的事物。
什么是敏捷
敏捷Agile是一组应对快速变化的软件开发方法,它的特点是迭代和增量。
敏捷通过尽早(迭代)地把产品(增量)投放到市场,帮助公司以最快的速度收到经济回报,同时收集市场用户对产品的反馈以最快的速度来改进产品。
- 迭代就是把项目从时间上等分成一段儿一段儿的。
- 增量就是每段时间里我完成的工作。能够卖给用户的功能才是我们所说的增量。
敏捷方式的核心思想在于迅速把产品投放给用户来为公司带来盈利。
核心思想在于迅速交付商业价值,体现为客工作的软件,以定期增量的方式持续地交付价值。
对于公司来说,敏捷开发的目的就是尽早开发出可以工作的产品给用户来赢得市场带来利润。在产品投放市场以后,通过客户的反馈,公司可以继续改进产品功能。
而实现这一目的的过程就是,项目被分成若干个迭代(迭代),每段时间里开发出一部分产品功能(增量),并且按照计划将这些功能(增量)投放到市场成为为公司盈利的产品。
与传统管理方法提前做好计划,尽量规避变化的管理方式不同,敏捷拥抱需求和技术的变化,认为需求和技术的不明确和变化是必然的。
敏捷宣言
敏捷的特点是迭代,每个迭代都提交一些增量。每一个要完成的功能为一个故事。
不论团队内外,传递信息效果最好效率也最高的方式是面对面的交谈。
可工作的软件是进度的首要度量标准。
敏捷过程倡导可持续开发。责任人、开发人员和用户要能够共同维持其步调稳定延续。
敏捷之伞
按照敏捷之伞的划分,可以将敏捷的各种方法分为两个部分:
轻量级的方法(服务于单个团队的方法)
- Scrum
- Lean software development
- Kanban (process+method)
- Extreme Programming (XP)
- Continuous Integration (CI)
- Continuous Delivery (CD)
- Feature Driven development (FDD)
- Test Driven Development (TDD)
- Crystal Clear
全面的方法(服务于多个敏捷团队的方法)
- Scrum-of-Scrums
- Scrum at Scale (Scrum@ Scale)
- Large-scale Scrum (Less)
- Scaled Agile Framework (SAFe)
- Disciplined Agile Delivery (DAD)
- Dynamic Systems Development Method (DSDM)
- Agile Project Management (AgilePM)
- Agile Unified Process (AUP)
- Open Unified Process (OpenUP)
在轻量级方法中,又可以从方法解决的问题这个角度将它们分为两类,其中,Scrum、Kanban都是生产产品的框架,用于产品开发或工作管理。而XP(极限编程)、FDD(特征驱动开发)则是工程实践类的方法。
在全面的方法中,根据不同的项目规模和团队之间工作的耦合度,有多个方法来协调多个敏捷团队的协同工作(如SAFe、Scrum-of-Scrums、LeSS等)。
方法简介:
- Scrum:作为最受欢迎,使用最为广泛的敏捷方法,Scrum是一种迭代的增量化过程,用于产品开发或工作管理。它是一种可集合各种开发实践的经验化过程框架。Scrum项目中发布产品的重要性高于一切。
- Kanban:Kanban是一种源于丰田精益化管理的方法,它是仅次于Scrum的另外一种敏捷软件开发的框架方法。它有以下特点:流程可视化,限制WIP(Work In Progress,在制品数量),度量生产迭代(没有固定时长的迭代)。相对于Scrum更适于开发新产品,Kanban则更加适合于运营维护团队实施敏捷时使用。
- XP:XP(Extreme Programming,极限编程)的思想源自Kent Beck和Ward Cunningham在软件项目中的合作经历。XP注重的核心是沟通、简明、反馈和勇气。因为知道计划永远赶不上变化,XP无须开发人员在软件开始初期写出很多的文档。XP提倡测试先行,为了将以后出现bug的概率降到最低。在XP的12个团队实践中,TDD(软件驱动开发)是其中之一。它的原理是在开发功能代码之前,先编写单元测试用例代码,测试代码确定需要编写什么产品代码,即通过测试来推动整个开发的进行。
- FDD:FDD(Feature-Driven Development,特性驱动开发)由Peter Coad、Jeff de Luca、Eric Lefebvre共同开发,是一套针对中小型软件开发项目的开发模式。此外,FDD是一个模型驱动的快速迭代开发过程,它强调的是简化、实用、易于被开发团队接受,适用于需求经常变动的项目。
- Scrum-of-Scrums:SoS是一种管理大型Scrum团队的技术(团队多于12人,被划分为5~10人一组的Scrum小组)。每一个小组都选出一名代表成员去参加所在团队的每日会议(也叫作Scrum of Scrums会议)。根据不同团队的需求,这些代表可以是工程师或ScrumMaster。通过Scrum of Scrums会议达到小组之间的信息同步,解决问题的目的。
- SAFe:SAFe(The Scaled Agile Framework)是一个企业级的敏捷管理框架,适用于管理大型的Scrum团队。SAFe框架提供了三层管理模型,分别由项目组合、项目集、实施团队构成。
符合敏捷思想的方法就都是敏捷方法,方法本身没有好坏之分,只看哪种方法更加适合当前项目的需要。
敏捷怎么工作
敏捷的工作方式:
将项目要实现的产品功能分解成一些小的产品功能(最常用的描述这些产品功能的技术就是用户故事),并且给这些产品功能条目排列优先级,然后在被称为迭代的一段时间迭代里逐一完成这些功能。
迭代变化,增量开发,故事引导
敏捷和瀑布模型的区别
瀑布模型是一个迭代模型,一般情况下将其分为计划、需求分析、概要设计、详细设计、编码以及单元测试、测试、运行维护等几个阶段。
计划,分析,设计,实施,测试,部署,维护
传统的瀑布模型项目面临着质量、可见性不高而风险太多,无法应对变化的问题。
- 质量不高
- 可见性不高
- 太多风险
- 无法应对变化
敏捷有以下特点:
- 需求分析,设计,编码和测试的工作是持续进行的。
- 产品开发过程是迭代的。
- 计划更加灵活,可以调整。
- 项目成员为了同一个目标努力,做出力所能及的奉献;而不强调”角色”的分工和明确的职责划分。
- 拥抱变化,及时调整。
- 交付可工作的软件是最重要的衡量项目是否成功的标志。
什么是Scrum
Scrum项目在时间上被划分为若干个冲刺,每个冲刺一开始团队都会从产品列表中选择一些用户故事放入冲刺列表。然后,团队开始在这些用户故事上工作。
冲刺(可以把它理解为Scrum里面对迭代的称呼),就是一个固定的时间长度,当时间一到冲刺即结束。
Scrum是一个框架,在此框架中人们可以解决复杂的自适应难题,同时也能高效并创造性地交付尽可能高价值的产品。
Scrum作为一个框架,它的最大特点就是迭代和增量。
项目以一个迭代接着一个迭代的方式运转,每个迭代的产出就是产品增量。在迭代当中,项目组每天都进行检查和调整。每个迭代的工作内容就是实现产品列表上的功能。
Scrum的工作方式:在每个迭代开始的时候,Scrum团队找出他们要做的产品列表条目。然后开始在这些条目上工作。并且在迭代结束的时候完成这些条目成为潜在可发布的产品增量
每个迭代团队的输入和输出:输入待实现的产品功能(用户故事),输出可交付的商业价值(产品增量)。
Scrum框架
Scrum通过三个角色——产品负责人、ScrumMaster、开发团队——来完成一系列的流程:计划会议,每日站会,评审会议,回顾会议,工件,产品列表,冲刺列表,潜在可交付产品增量以实现迭代,增量开发。
- 产品负责人是有授权的产品领导力核心,一方面他担任着产品经理的角色以确保能开发出正确的解决方案,另一方面他还必须和开发团队交流以保证特性的接受标准有明确的说明(用户故事)并且已经满足后续需要运行测试验收的标准,以确保特性完成(业务分析师和测试人员的部分工作)。这个角色责任重大,负责构建正确的产品。
- ScrumMaster负责帮助每个人理解并乐于接受Scrum的价值观、原则和实践。对开发团队和产品负责人来说,ScrumMaster履行的是教练、过程领导的职责。他负责帮助团队和组织其他成员发展具有组织特色的、高效的Scrum方法。
- 开发团队是主任工程师、开发、测试工程师、数据库管理员、界面设计工程师和其他传统软件开发方法当中定义的不同工作类型的所有类型的人的跨职能的集合。开发团队负责用正确的方法构建产品。
- 冲刺(Sprint)是Scrum的核心,它的持续时间为一个月或者更短(两周的Sprint长度在实践中是最为广泛的),在这段时间内构建产品增量。在整个开发过程中,Sprint的长度都应该尽量保持一致。前一个Sprint结束后(以持续时间结束为标准来结束Sprint),下一个新的Sprint紧接着立即开始。
- 潜在可发布产品增量:在冲刺结束时,团队应当得到一个潜在可发布产品(或者产品增量)。如果业务上适合,就可以发布;如果不适合在每次冲刺后发布,可以把多个冲刺的一组特性合并在一起发布。
- 产品列表:是一个按优先级排序的、有粗略估算的、成功开发产品所需特性及其他功能的列表。在产品列表的指导下,我们总是先做优先级最高的条目。换句话说就是,当一个冲刺完成时,已完成的条目都是优先级最高的。
- 冲刺计划会:一般情况下,产品列表中的工作量远远不是一个短期冲刺内能够完成的。所以冲刺开始时,团队需要制订计划,说明在下一个冲刺中要创建产品列表中的哪几个高优先级的特性(产生Sprint列表)。
- Sprint列表(Scrum Guide中也称之为Sprint待办列表):是一组当前Sprint选出的产品待办列表项,同时加上交付产品增量和实现Sprint目标的计划(包括每个待办列表项完成所需要的估算等)。
- 冲刺评审会和回顾会:在冲刺结束时,团队与利益干系人一起评审已经完成的特性,获得它们的反馈,产品负责人和团队既可以对下一步工作内容进行修改(在评审会上),也可以修改以前的工作方式(在回顾会上)。评审会上,如果利益干系人在看到一个完成的特性时,意识到自己没有考虑到另一个必须包含在产品中的特性,此时,产品负责人只需要建立一个代表该特性的新条目,并把它以适当的顺序插入产品列表,留到后面的冲刺中完成。回顾会上,如果开发团队在回顾冲刺过程中,意识到自己没有考虑到依赖风险导致开发过程不必要的等待时,开发团队可以提出下一冲刺计划会上考虑依赖风险并做好相应的控制。
- 每日站会:是整个Scrum里面非常有特点的一个会议。它是开发团队的一个时间限制在15分钟以内的会议(时间盒=15分钟)。名副其实,每日站会需要每天都举行。这个会议的目的是实现开发团队每天对完成Sprint目标的进度和Sprint待办列表的工作进度趋势的检视,并且做出相应的调整和适应。
实践类问题
组织文化就是组织成员的行为。
PRINCE2是一个过程驱动的项目管理方法论。它是基于7个基本原则的:持续的业务验证,经验学习,角色与责任,按阶段管理,例外管理,关注产品,根据项目环境剪裁。PRINCE2关注于项目的计划和控制。
Scrum是基于经验主义的,所有的问题都是基于经验逐步解决的。Scrum是自组织的,请依靠和相信你的团队,他们是真正创造价值的人。
只有Scrum的所有部分都执行了它才是Scrum。
Scrum是一个框架,而不是一个方法。
框架和方法之间的差别就在于,方法预示着一个放之四海皆准的、格式化的途径,就好比PRINCE2、PMP都是方法;但是框架相比之下就更灵活,它是一个平台,根据环境的不同,它可以提供一系列不同的途径。
Who - Scrum的角色
ScrumMaster
作为Scrum流程的捍卫者和布道者,ScrumMaster。
在实践层面上,一般都是项目经理转做ScrumMaster的实践居多。
ScrumMaster的职业发展路线通常会有如下4个方向:
(1)服务于多个团队或者更具挑战性的团队。
(2)成为Agile Coach
(3)成为产品负责人。
(4)成为管理者。
把Agile Coach的成长之路分成三个逐步跃升的层级:
- 敏捷团队的协调者 - 擅长技术领域(开发出身)
- Agile Coach - 擅长商务领域(产品负责人出身)
- 企业级Agile Coach - 擅长变革领域(ScrumMaster)
技术领域(开发出身)、商务领域(产品负责人出身)和变革领域(ScrumMaster)出身。
ScrumMaster是一位服务型领导,通过服务于团队之外的人以及团队中的各个角色来促进和支持Scrum,其中包括但不限于推动阻碍团队工作的事情,引导Scrum流程,协调团队内外的沟通,隔离团队的外部干扰等。
所谓的服务型领导,可以把它简单地理解为和传统的项目经理的命令式领导是相区别的。对于传统的项目经理来说,他对项目负最终的责任,因此他也就同时被赋予了领导项目成员的权利。
ScrumMaster的主要职责:
(1)教练——指导Scrum团队。
(2)Scrum专家——Scrum团队的过程专家,引导Scrum的流程。
(3)推土机——推动一切阻碍开发团队工作的问题。
(4)保护伞——保护开发团队免受外部的干扰。
(5)服务型领导。
产品负责人
产品负责人的工作包括:愿景和边界。产品负责人的工作包括两个方向:提出正确的解决方案和确保解决方案被正确“制造”。
产品负责人的职责是将开发团队开发的产品价值最大化。
产品负责人是负责管理产品待办列表的唯一负责人。
产品负责人在Scrum团队里对‘做什么’‘做成什么样’有最终话语权。
产品负责人负责团队“做什么”,提供产品的愿景和边界,与利益干系人、开发团队合作,以便帮公司得到最高投资回报。
产品负责人的主要职责:
- 提供愿景和边界。
- 代表客户和业务。
- 拥有产品列表,故事优先级的唯一决定者。
- 设立故事的接收标准。
- 和项目相关团队、干系人沟通。
愿景展示了产品会变成什么样;而边界则描述了愿景被实现时的现实情况。边界由产品责任人提供并经常表示为限制条件。
Scrum组织中项目管理职责的映射:
| 项目管理活动 | 产品负责人 | ScrumMaster | 开发团队 | 其他经理 |
|---|---|---|---|---|
| 集成 | √ | √ | ||
| 时间 | 宏观层面 | 帮助Scrum团队有效利用时间 | 冲刺层面 | |
| 范围 | 宏观层面 | 冲刺层面 | ||
| 成本 | √ | 故事/任务评估 | √ | |
| 质量 | √ | √ | √ | 编队 |
| 团队(人力资源) | √ | √ | ||
| 沟通 | √ | √ | √ | √ |
| 风险 | √ | √ | √ | √ |
| 采购 | √ |
开发团队
简单来说完成用户故事的流程可以是:待办→工作中→完成。
区别于传统开发方法里的“只负责自己那一部分工作”,作为一个整体,团队对功能的实现负责。
所谓跨职能就是指为了提交潜在可交付的增量,团队需要具备所有相应知识和技能的成员。
Scrum的开发团队应该由T型技能的成员组成。所谓T型的意思就是团队的成员在广度(知识结构和能力)和深度(专业知识)两个维度都有发展。
Scrum团队的自组织。所谓自组织就是团队自下而上,自发地管理和控制,也因此区别于传统的靠外部的统治力的管理方式。
组织的系统最有意思的特点是它拥有非凡的稳定性和产生惊人的新颖性。
在自组织的团队里,团队成员通过讨论达成共识并且最终制定规则和流程。由于每个团队成员都可以对所有议题发表自己的意见而成为规则和流程的制定者,因此当最后达成一致意见后,团队成员就会更加主动地去履行他们的承诺
Scrum开发团队的主要职责如下:
- 在冲刺执行期间,开发团队完成创造性的工作,包括设计,构建,集成,测试,最终提供潜在可发布的功能发布。
- 每日检视和调整(每日站会)——作为一个自组织的团队,团队通过每日站会来实现自我的检视和调整以实现冲刺目标。
- 梳理产品列表——帮助产品负责人梳理产品列表,细化产品列表条目,估算和排列优先级。
- 冲刺规划——在每个冲刺之初,开发团队参与冲刺计划会议。在会议上,根据产品经理提供的信息,对产品列表条目的工作量进行估算,并在ScrumMaster的指导下,与产品负责人共同制订冲刺目标。
- 检视和调整产品与过程——在每个冲刺结束的时候,开发团队都需要参加冲刺评审会议和冲刺回顾会议。在会议上,Scrum团队检视和调整自己的过程和技术以进一步改善团队使用Scrum来交付业务价值的能力。
Scrum开发团队的特征如下:
- 自组织——没有项目经理或者其他经理告诉团队怎样开展工作;团队在没有外部力量干预的情况下,为了共同的冲刺目标而工作,逐渐达成默契,相互理解,不断改进。
- 跨职能——为了提交潜在可交付的增量,团队需要具备所有相应知识和技能的成员。
- 规模适中——5~9人的规模。
Scrum强调团队作为一个整体承担责任。
在Scrum团队里整个团队对质量负责,而不应该将质量的责任只记在QA的名下。
Scrum的核心价值观:活力,共情,好奇,友善,尊重。
实践类问题
产品负责人负责产品要做成什么样,但不负责指导团队。
ScrumMaster则负责另外一个维度的工作,即专注于帮助团队以正确的方式和流程来执行Scrum项目。
在团队中,产品负责人代表组织对经济利益的追求,而ScrumMaster则代表团队的利益。
迭代和冲刺的区别:
迭代的英文为Iteration。迭代是一个通用的敏捷术语,指的是单个开发迭代。
冲刺的英文为Sprint。作为敏捷的一种方法的Scrum,冲刺是指Scrum的一个迭代。如果把语境局限在Scrum的话,迭代和冲刺指的都是一回事儿。
How - Scrum工件
产品列表
产品列表由各个待办事项组成,每一个待办事项称之为产品列表条目。按照性质区分,可以把产品列表条目大致分为:经常写成用户故事形式的特性、缺陷、技术工作和知识获取。
在Scrum当中,产品列表是最为核心的工件,也是被应用最为广泛的工件。
用户故事的格式是最为普及的产品列表条目格式:作为一个……我想……这样我就可以……。
使用T-Shirt Size技术进行估算,将用户故事大小分为S、M、L、XL。
史诗级故事是用来描述大型用户故事的通用术语。
所谓技术故事,是指客户不感兴趣但又不得不做的事,例如,升级数据库,清除没用的代码,重构混乱的设计或者实现一个老功能的测试自动化。
不到万不得已,不要写独立的技术故事,最好尝试在与这个技术相关的某个功能性用户故事里面把它作为一个技术需求以任务的形式表达出来。
MoSCoW的技术来解决你的问题,它将需要做的产品功能分成4类:Must Have(必须有的功能),Should Have(应该有的功能),Could Have(可以有的功能)和Would Have(也许有的功能)。
产品列表应该具有如下特点:
- 详略得当:马上要做的条目要详细描述,短时间内不做的内容粗略。
- 涌现的:只要有正在开发或维护的产品,产品列表就永远不会完成或冻结。它会根据不断涌入的、具体的、有经济价值的信息持续更新。
- 做过估算的:每个产品列表条目都要有大小估算,相当于开发这个条目需要完成多少工作。
- 排列优先顺序的:对短期内要做的几个冲刺要仔细排好优先顺序。但是对于短期内不做的条目,除了给出一个大致的优先级,其他任何工作都是不值得做的。
一般情况下,产品列表需要至少包括以下信息:用户故事名称(列表条目)、功能模块、史诗级故事、描述、接收标准、状态和备注。
- 用户故事(列表条目):我们使用用户故事技术来描述产品列表条目。
- 功能模块:用户故事所属功能模块。
- 史诗级故事:“史诗级故事”(epic)是用来描述大型用户故事的通用术语。史诗级故事是一个我们觉得它“个头儿”有点儿大,因而需要进一步拆分的故事。
Sprint待办列表
Sprint列表是团队当前Sprint的任务清单。和产品列表不一样,它的寿命是有限的,仅在一个Sprint的时间里存活。它里面包含所有团队已承诺的故事以及相关联的任务,以及此外的附加工作。
(1)Sprint列表是一组为当前Sprint选出的产品待办列表项,同时加上交付产品增量和实现Sprint目标的计划。
(2)Sprint列表是开发团队对于下一个产品增量所需的功能以及交付这些功能到“完成”的增量中所需的工作的预测。
(3)为了确保持续改进,Sprint列表是少包含一项在前次回顾会议中确定下来的高优先级的过程改进。
(4)Sprint列表是拥有足够细节的计划,任何进度上的变化可以在每日展会中清晰地看到。开发团队在Sprint期间修改Sprint列表,使得列表在Sprint期间涌现(根据不断涌入的、具有经济价值的信息持续更新)。
(5)在Sprint期间只有开发团队可以改变Sprint列表。
(6)Sprint列表是高度可见的,是对开发团队计划在当前Sprint内工作完成情况的实时反映,由开发团队全权负责。
用户故事的分类:
- Epic - 最大的故事约为几个月的大小,可跨越一整个或多个版本,就是之前说的Epic(史诗级故事)。
- Feature - 第二个级别的故事的大小通常以周为单位,对单个冲刺来说还是有点儿大,有些团队称之为特性。
- Story - 最小的用户故事就是我们通常说的“故事”,或者冲刺故事,它足够小,可以放入一个冲刺完成。
- Task - 任务处于故事下面一级,通常是一个人独立完成的工作,或者也有可能是两个人结对完成。完成任务所需要的时间一般以小时记。
用户故事是要有用户交付价值的,但任务不是,任务就是工程师们具体的工作。
完成的定义
完成的定义(Definition of Done,DoD)成为一个指导开发工作的协议,清楚列出一项任务需要完成哪些工作之后才可以被归为完成。
完成的定义——非功能性需求:
- 可伸缩性:规模必须能扩充到同时支持2000个用户。
- 可移植性:使用的任何第三方技术都必须是跨平台的。
- 可维护性:所有模块都需要保持清楚的模块化设计。
- 安全性:必须通过具体的安全渗透测试。
- 可扩展性:必须确保数据接入层可以和所有商用关系型数据库相连。
- 互操作性:必须能够实现套件中所有产品的数据同步。
从概念上来说,完成的定义是在宣布工作潜在可发布之前要求团队成功完成的各项工作检查。
在大多数情况下,完成的定义至少要产生一个产品功能的完整切片,即经过设计,构建,集成,测试并编写了文档,能够交付已验证的客户价值。
完成的定义具有如下的特点:
- 完成的定义可以随时间演变。
- 完成的定义和接收标准不同(当某个“接收标准”里的需求适合于所有的用户故事,那么它就是完成标准里的一项;但如果该需求只是适用于所有用户故事的一个子集,那么它就是这个用户故事子集里的故事的验收标准)。
- 完成的定义可以是多个不同层面的(任务层面,用户故事层面,交付层面)。
- 完成的定义里会包含一些限制因素(可移植性,可伸缩性,可维护性,安全性,可扩展性,互操作性)。
监测
Sprint燃尽图用于显示当前冲刺剩余工作量的变化。
交付燃尽图便于产品负责人跟踪发布剩余工作随时间变化的过程。
燃尽图描述了剩余工作随时间变化的轨迹。纵坐标绘制剩余工作量,横坐标是时间。通常来说,团队不断地完成任务,剩余工作量也应该随之下降。这会呈现为一条从左到右向下延伸的斜线。
实践类问题
DoR = Definition of Ready 准备就绪的定义
产品负责人管理产品列表,但维护产品列表的责任团队成员人人有之。
产品列表的梳理是包括产品负责人、ScrumMaster、研发团队在内的整个团队的责任。
Sprint待办列表,它是在每个冲刺的计划会议当中产生的。在进入Sprint阶段以后,团队成员负责维护和更新Sprint待办列表。
敏捷要做的是减少浪费,以便能按照项目的特点灵活选择文档的数量与形式,在过度设计和返工之间寻找到平衡。
What - Scrum会议
计划会议
最常用的估算产品列表条目的单位是故事点和理想天数。
故事点就是用于衡量产品列表条目的大小和数量。(Sprint(n-1)故事点数/Sprint(n-1)工作人·天数=Sprintn故事点数/Sprintn工作人·天数)
Sprint中要做的工作在Sprint计划会议中来做计划。Sprint计划会议是由时间盒限定的。ScrumMaster要确保会议顺利进行,并且每个参会者都了解会议的目的。
Sprint会议回答以下两个问题。
(1)这个冲刺能做什么?
Sprint会议的输入是产品待办列表,最新的产品增量,开发团队在这个Sprint中能力的预测以及开发团队的以往表现。
(2)如何完成所选的工作?
每日站会
每日站会也是通过会议的形式把大家组织到一起来检视和调整的.
每日Scrum站会是开发团队的一个时间盒限定为15分钟的事件。在每日站会中,开发团队为接下来的24小时的工作制订计划。通过检视上次每日站会以来的工作和预测即将到来的工作来优化团队的协作和效能。每日站会在同一时间同一地点举行,以便降低复杂性。
每日站会是开发团队的内部会议。如果有开发团队之外的人出席会议,ScrumMaster必须确保他们不会干扰会议进行。
开发团队借由每日站会来检视完成目标的进度,并监视完成Sprint待办列表的工作进度趋势。每日站会优化了开发团队达成目标的可能性。
以下是一个可以使用的会议议程范例:
(1)昨天,我为帮助开发团队达成Sprint目标做了什么?
(2)今天,我为帮助开发团队达成Sprint目标准备了什么?
(3)是否有任何障碍在阻碍我或开发团队达成Sprint目标?
评审会议
评审会议更重要的是为了收集项目干系人的各种反馈,达到检视和调整的目的。
这是一个非正式会议,并不是一个进度汇报会议,演示增量的目的是为了获取反馈并促进合作。
评审会议的目的是参与者深入交谈,合作讨论出建设性的建议和意见。而演示实际上只是展示工作的一种途径。
评审会议的另外一个目的是要和与会的项目干系人一起对下一个Sprint要做的产品列表达成共识。
Sprint评审会议的结果是一份修订后的产品待办列表,阐明很可能进入下个Sprint的产品待办列表项。产品待办列表也有可能为了迎接新的机会而进行全局性的调整。
| 来源 | 描述 | 目的 |
|---|---|---|
| Scrum团队 | 产品负责人,ScrumMaster和开发团队 | 听到反馈,回答问题 |
| 内部利益干系人 | 业务负责人、管理人员、经理 | 检查进展,提出建议 |
| 内部利益干系人 | 销售、市场营销、支持、法律 | 提出相关领域的反馈 |
| 外部利益干系人 | 外部客户、用户、合作伙伴 | 提供反馈 |
回顾会议
回顾会议的目的是检视和调整Scrum团队的流程。
Scrum项目就是一个不断调整,拥抱变化,不停迭代的过程。
没有评审过测试用例的用户故事研发不能开始代码工作。
不要试图改变团队成员的个性,而是要找到他们最舒服的讨论问题的方法。
回顾会议的内容:
(1)会议目的——检视和调整Scrum团队的流程。
(2)会议时间——每个ScrumCycle的最后一个会议(推荐开会时间是每个Sprint最后一天的下午)。
(3)时间盒:≤2小时(两周的Sprint)。
(4)会议讨论的问题:
- 检视前一个Sprint中关于人、关系、过程和工具的情况如何。
- 找出并加以排序做得好的和潜在需要改进的主要方面。
- 同时,制订改进Scrum团队工作方式的计划
实践类问题
安全检查是通过匿名调查来了解团队整体对会议的安全感的情况。
附录:参考概念
小瀑布:虽然使用了Scrum的各种仪式,把迭代也变短了,但还是在按照瀑布的习惯和工作方式工作,而没有思考敏捷的核心价值的团队工作方式。
时间盒 Time boxing:是一种管理方法,即在预算时间内对完不成的功能进行删减或者延迟,而不是拖延预算的时间。就是“后墙不倒”。
一个“Time box”是一个比较短而且固定长度的时间段。在这个时间段中,团队成员要为满足一个特定的目标做出努力。这个目标可以是一批功能需求或技术需求,也可以是满足一个发布目标(例如,beta测试应支持150个用户),还可以是完成一个可运行的原型等。
增量开发,是一块接着一块地构建一个系统。一部分功能被先开发出来,然后另一部分功能被加入到前一部分功能中,以此类推。
迭代开发,是“重做调度策略”。迭代开发过程认为:第一次能做好某个特性是不可能的事(至少是不大可能的事)。
在一个增量过程中,我们完全地开发一个特性,然后再进入下一个;而在一个迭代的过程中,我们构建整个系统,但在一开始做得并不是那么完美,而是利用后续机会对整个网络进行各种改进。
敏捷软件开发宣言:
价值观:
个体和互动 高于 流程和工具
工作的软件 高于 详尽的文档
客户合作 高于 合同谈判
响应变化 高于 遵循计划敏捷宣言遵循的原则:
我们最重要的目标,是通过持续不断地及早交付有价值的软件使客户满意。
欣然面对需求变化,即使在开发后期也一样。
为了客户的竞争优势,敏捷过程掌控变化。
经常地交付可工作的软件,相隔几星期或一两个月,倾向于采取较短的迭代。
业务人员和开发人员必须相互合作,项目中的每一天都不例外。
激发个体的斗志,以他们为核心搭建项目。
提供所需的环境和支援,辅以信任,从而达成目标。
不论团队内外,传递信息效果最好效率也最高的方式是面对面的交谈。
可工作的软件是进度的首要度量标准。
敏捷过程倡导可持续开发。
责任人、开发人员和用户要能够共同维持其步调稳定延续。
坚持不懈地追求技术卓越和良好设计,敏捷能力由此增强。
以简洁为本,它是极力减少不必要工作量的艺术。
最好的架构、需求和设计出自自组织团队。
团队定期地反思如何能提高成效,并依此调整自身的举止表现。
三大支柱:透明、检视、适应。
| 支柱 | 定义 | 例子 |
|---|---|---|
| 透明 | 过程中的关键环节对于那些对产出负责的人必须是显而易见的。要拥有透明,就要为这些关键环节制定统一的标准,这样所有留意这些环节的人都会对观察到的事物有统一的理解 | 所有参与者谈及过程时都必须使用统一的术语负责完成工作和检视结果增量的人必须对“完成”的定义有一致的理解 |
| 检视 | Scrum的使用者必须经常检视Scrum的工件和完成Sprint目标的进展,以便发现不必要的差异。检视不应该过于频繁而阻碍工作本身。当检视是由技能娴熟的检视者在工作中勤勉地执行时,效果最佳 | Scrum规定了4个正式事件,用于检视与适应上,这4个事件在Scrum事件章节中会加以描述:Sprint计划会议,每日Scrum站会,Sprint评审会议,Sprint回顾会议 |
| 适应 | 如果检视者发现过程中的一个或多个方面偏离可接受范围以外,并且将会导致产品不可接受时,就必须对过程或过程化的内容加以调整。调整工作必须尽快执行如此才能最小化进一步的偏离 | (同上) |
五大价值观:承诺、勇气、专注、开放、尊重。
专有名词对照:
Agile 敏捷
Scrum 一种迭代方法
Iteration 迭代
Sprint 冲刺
Product Backlog 产品列表
Spring Backlog 产品待办列表
Devlop (Dev) Team 开发团队
Product Owner (PO) 产品负责人
Project Manager (PM) 项目经理
Planning Meeting 计划会议
Review Meeting 评审会议
Retrosppective Meeting 回顾会议
点评:Scrum入门教程。口水式的对话方式,一目十行。



